Framework
FlowR2A unifies the dense reward supervision of scoring-based methods with the dynamic proposal generation of anchor-based methods, all within a single generative model.
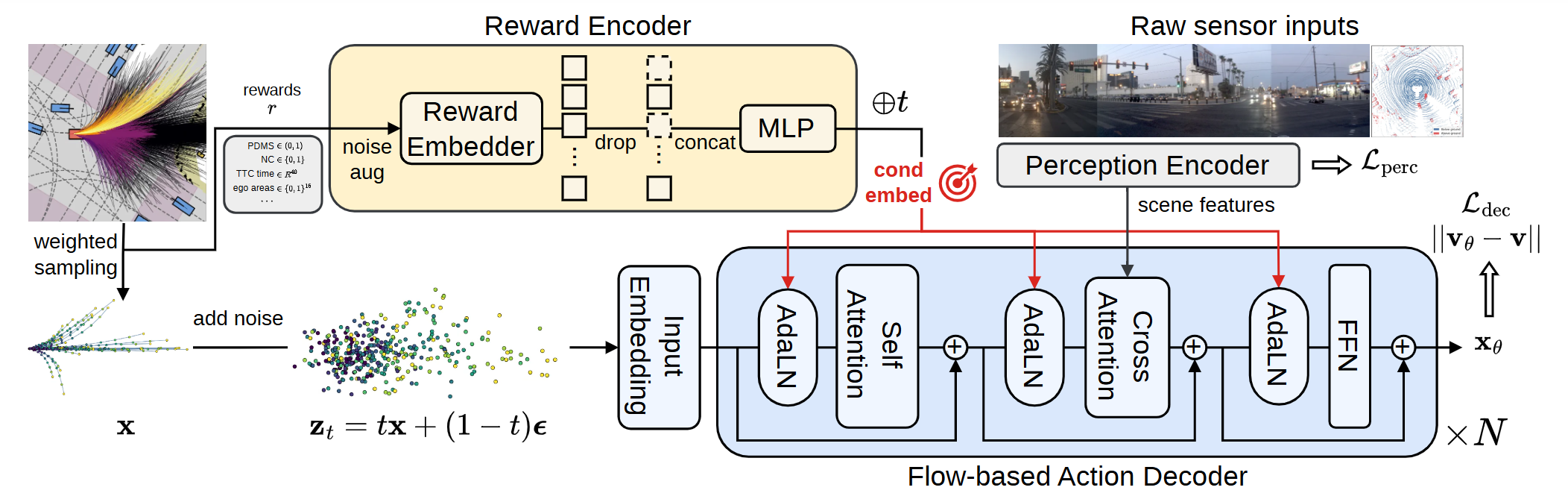
FlowR2A unifies the dense reward supervision of scoring-based methods with the dynamic proposal generation of anchor-based methods, all within a single generative model.
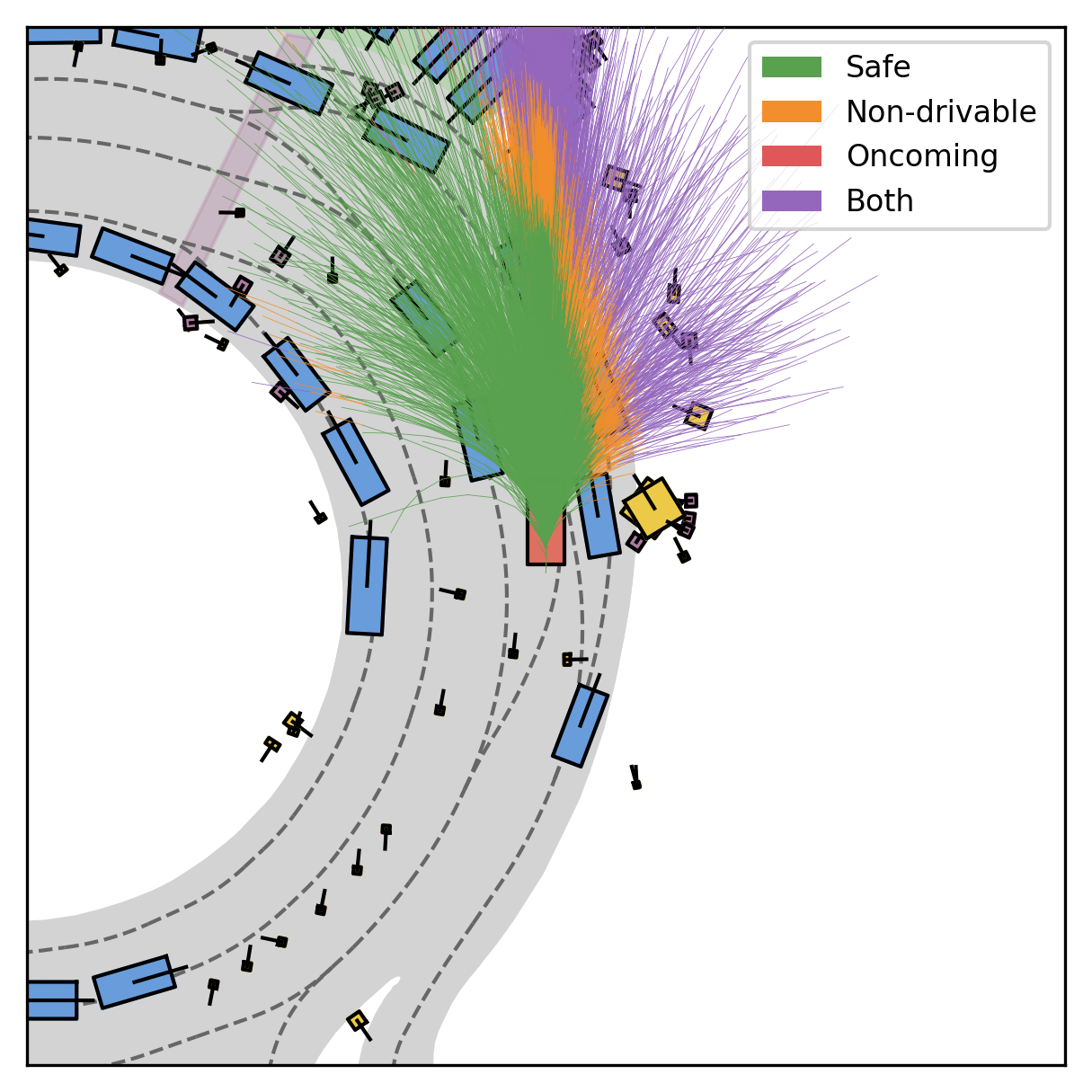
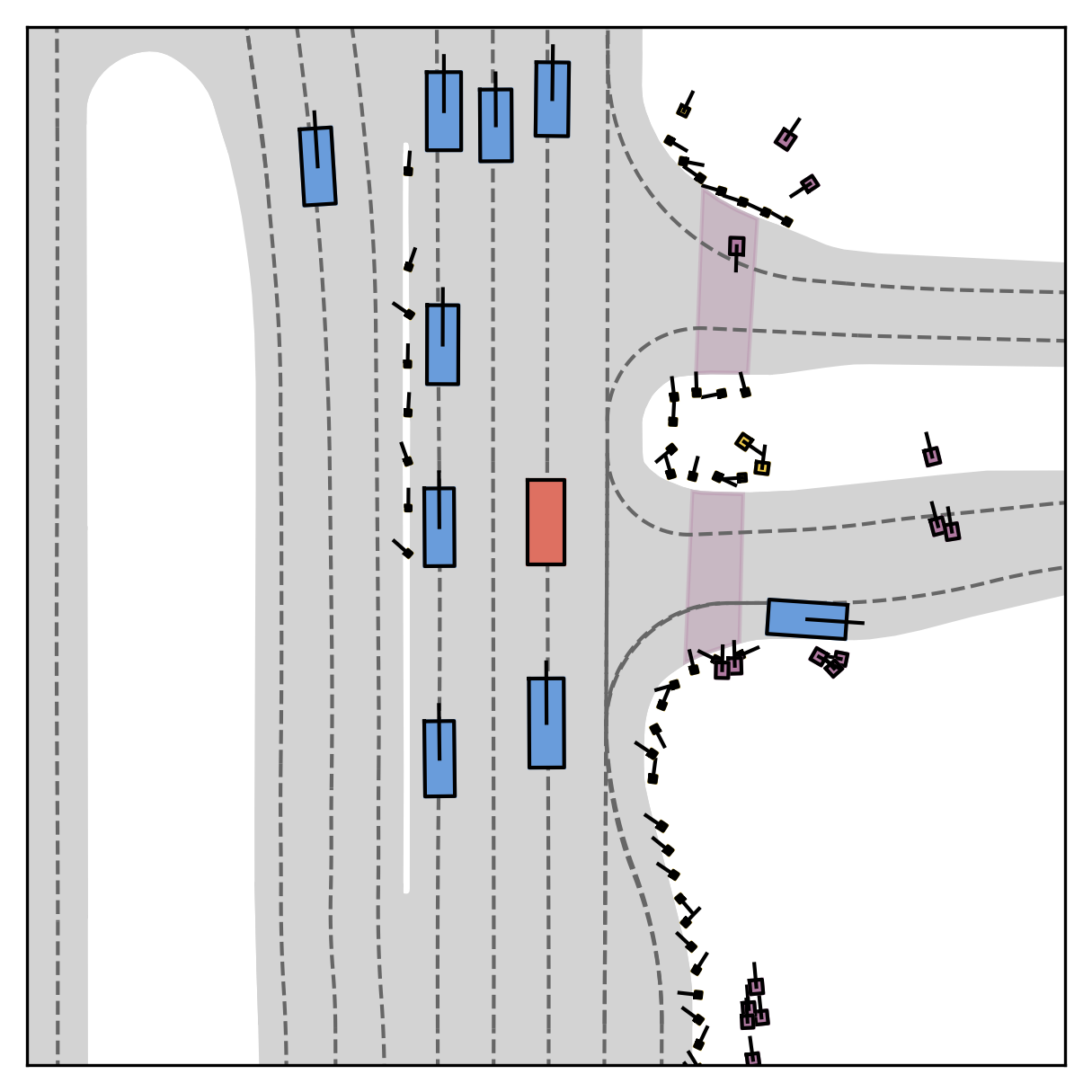
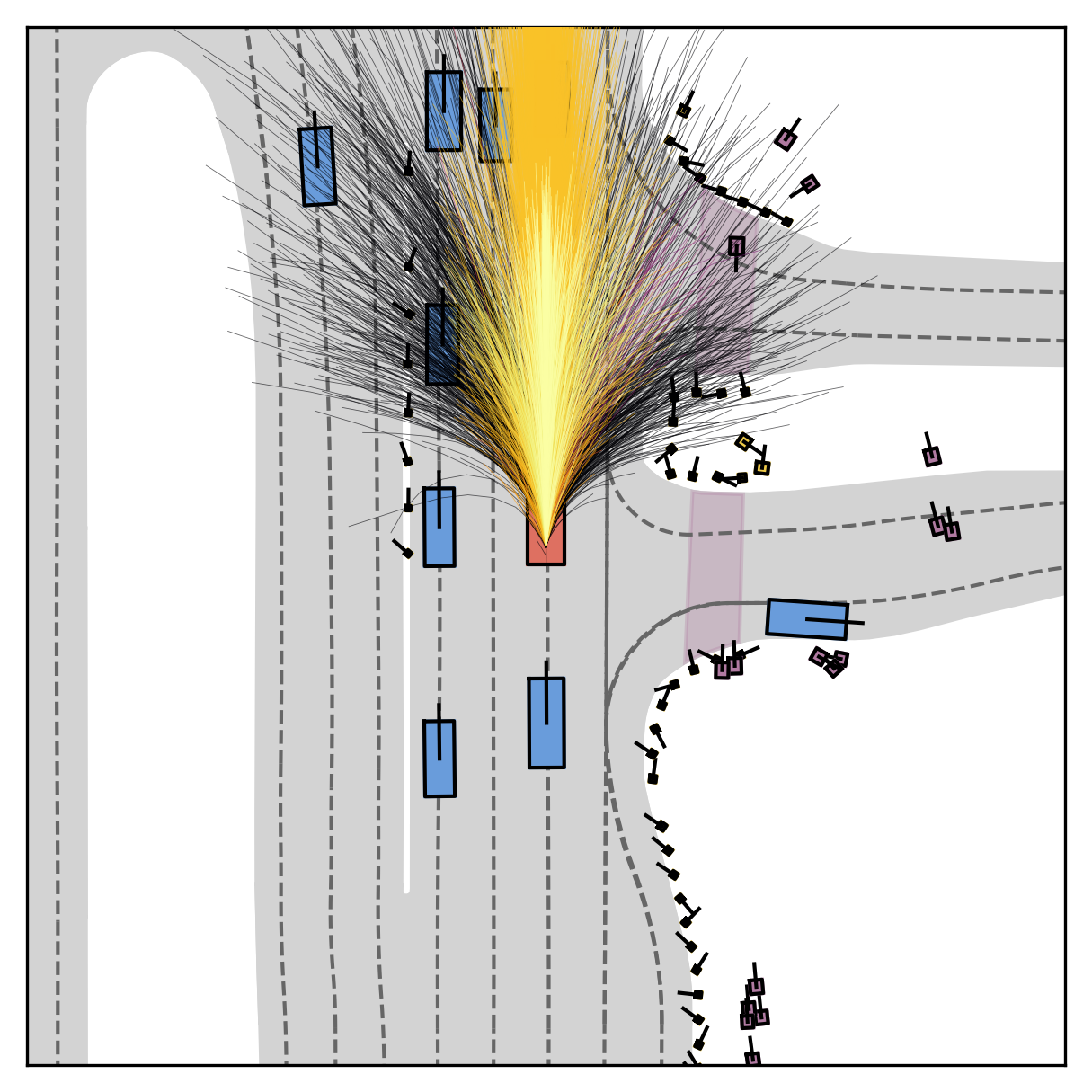
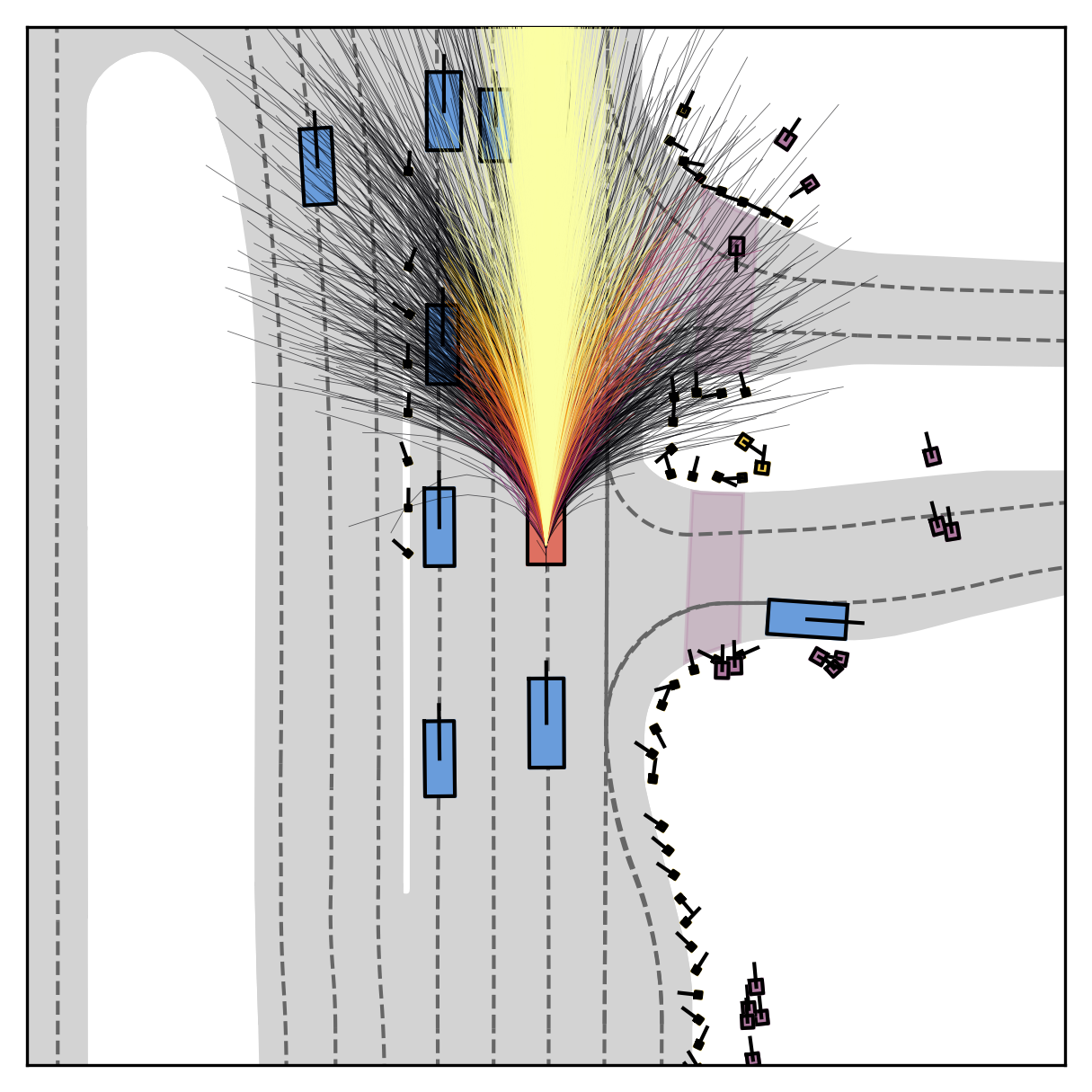
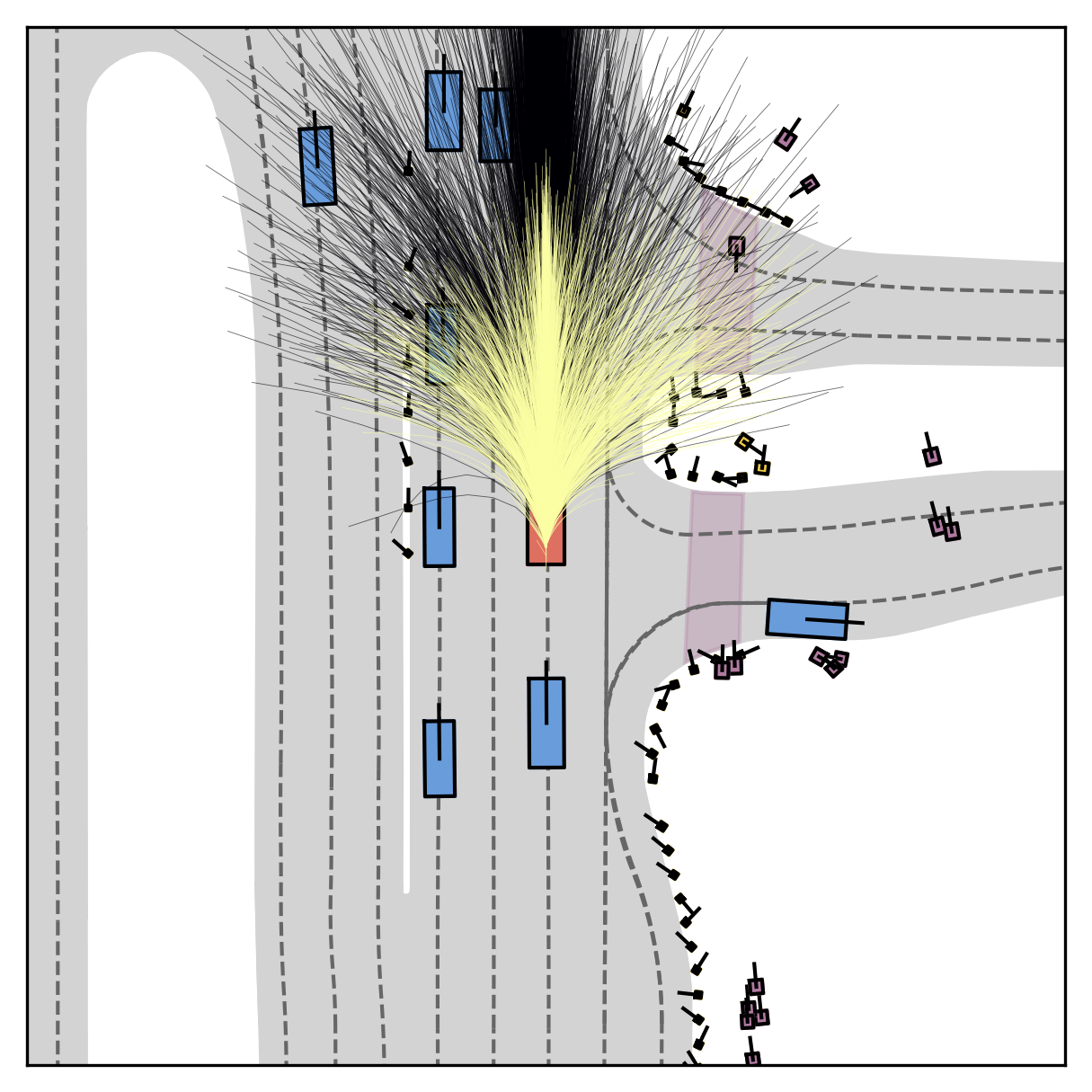
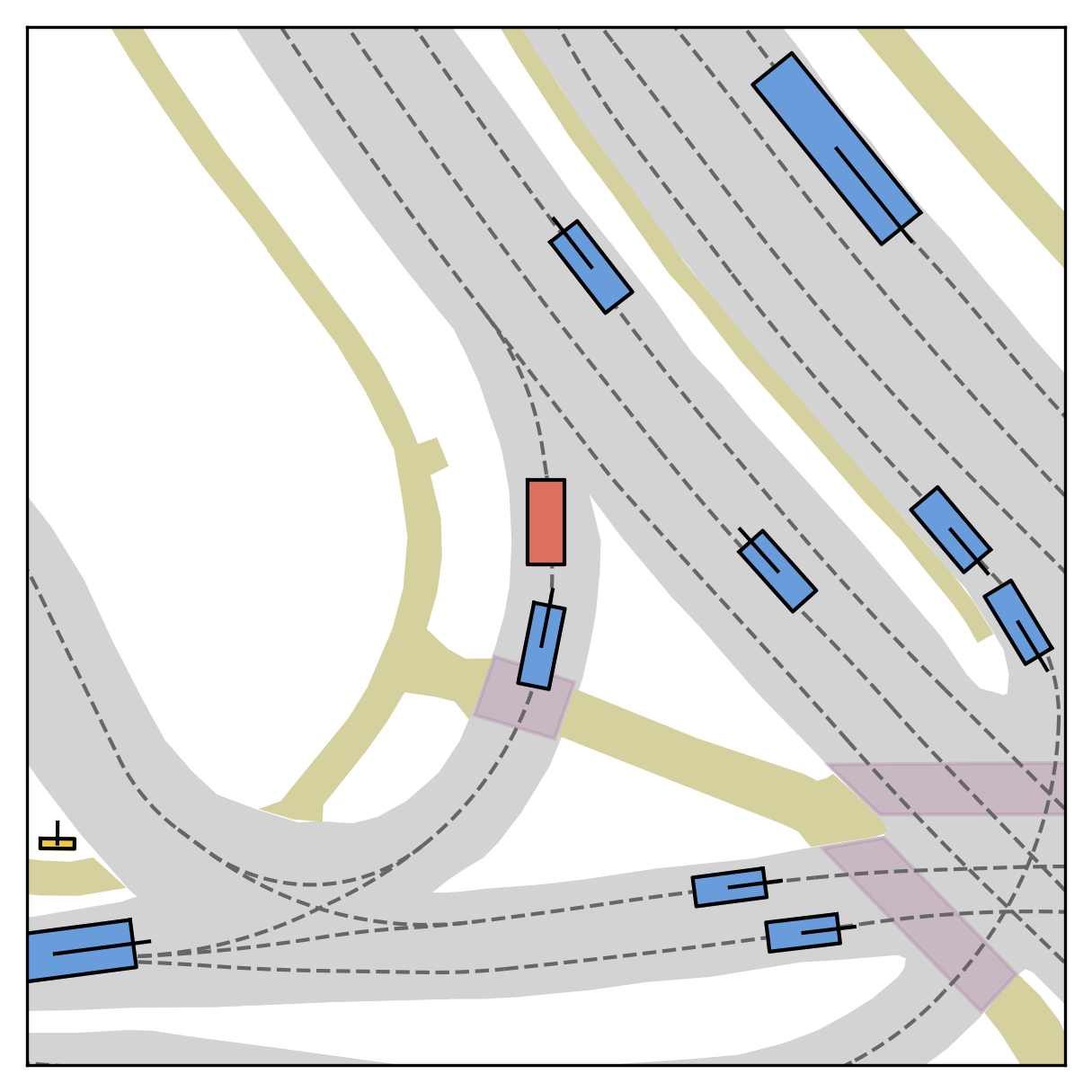
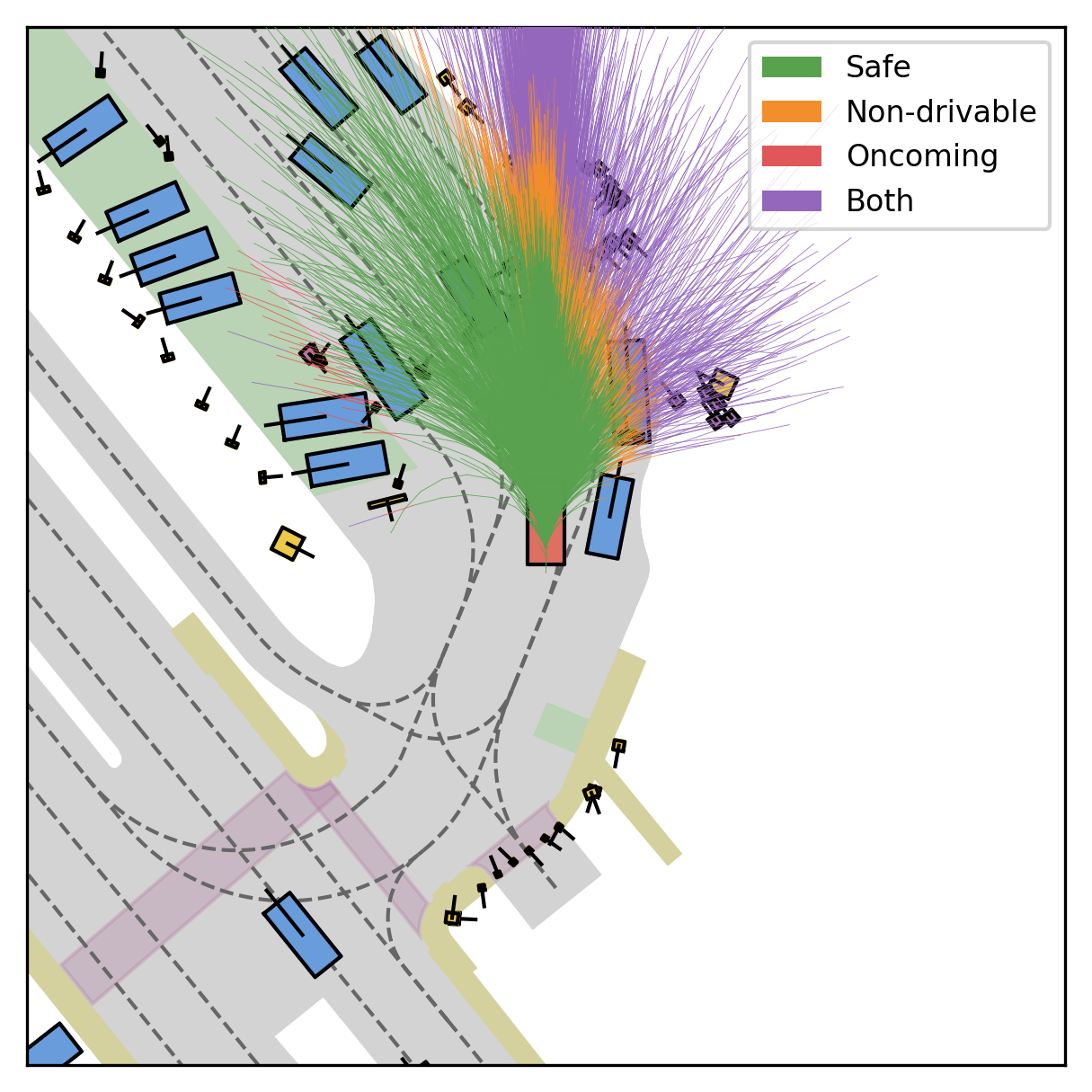
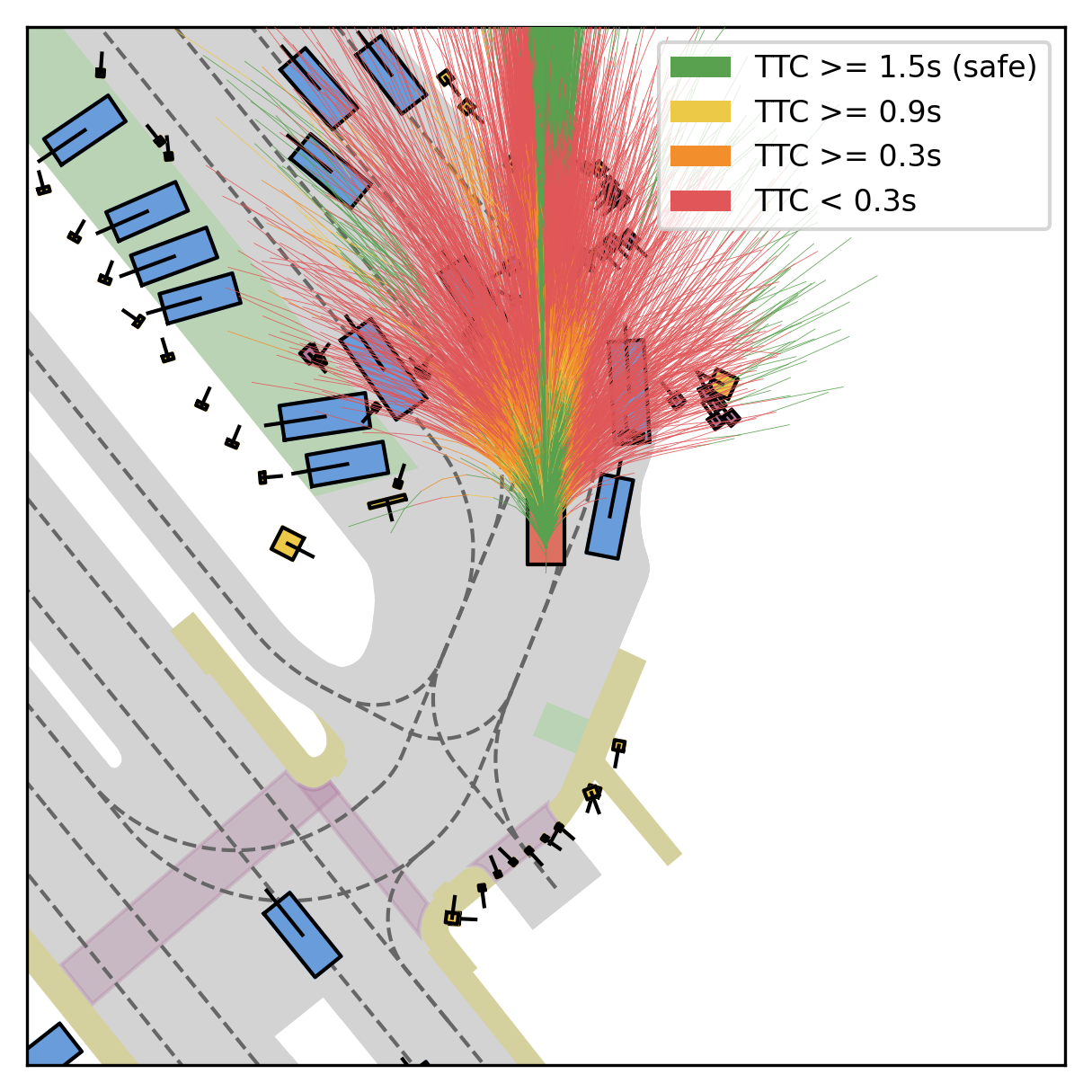
Each planner's proposals are colored by PDMS, from red (0) to green (1).
| DiffusionDrive | 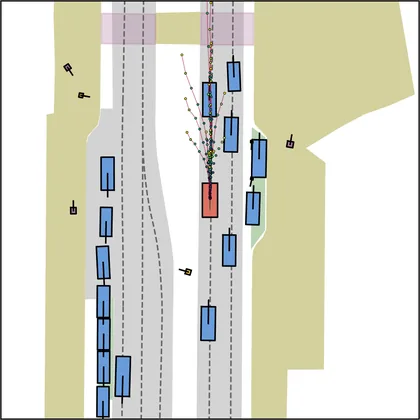 |  |
|---|---|---|
| DiffusionDriveV2 | 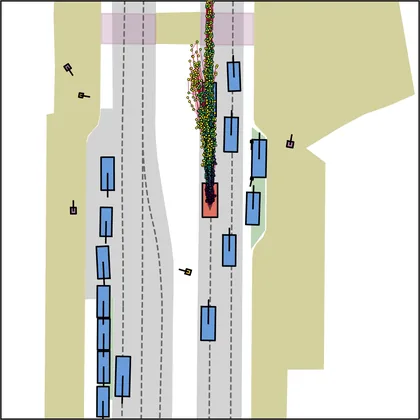 |  |
| iPad | 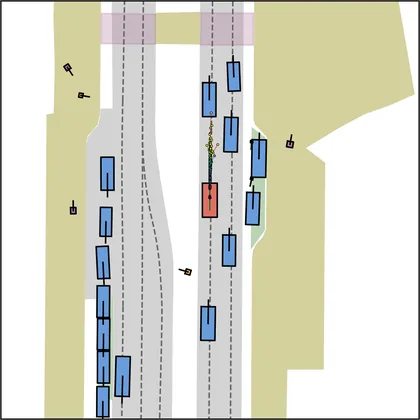 |  |
| FlowR2A (ours) | 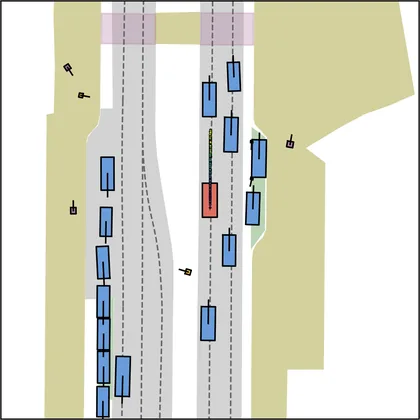 |  |
| DiffusionDrive | 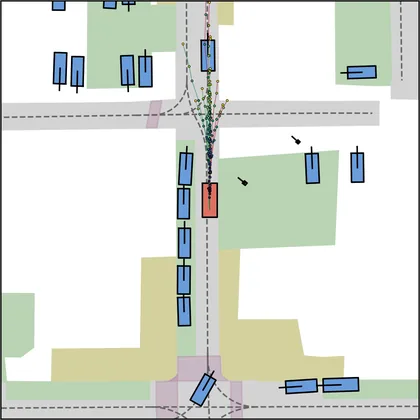 |  |
|---|---|---|
| DiffusionDriveV2 | 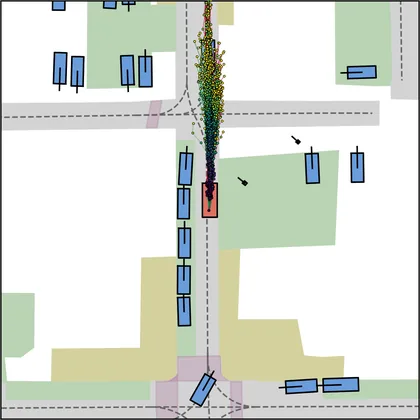 |  |
| iPad | 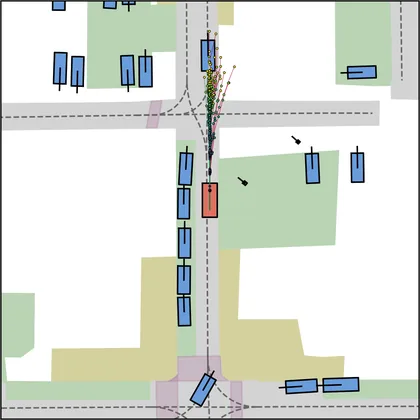 |  |
| FlowR2A (ours) | 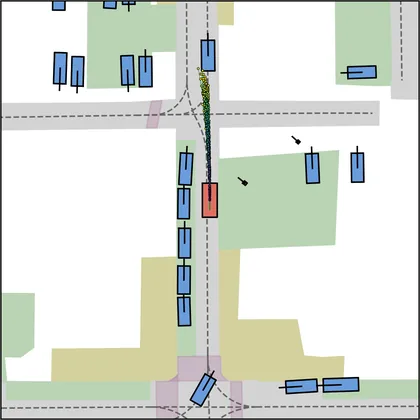 |  |
| DiffusionDrive | 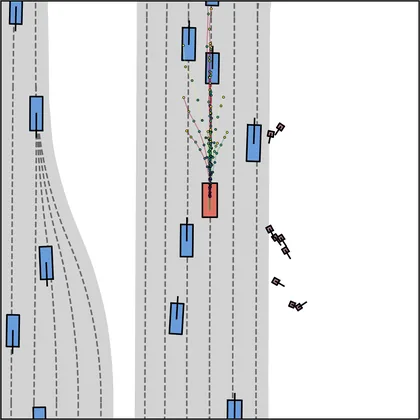 |  |
|---|---|---|
| DiffusionDriveV2 | 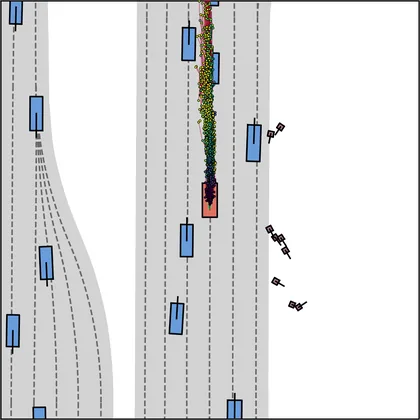 |  |
| iPad | 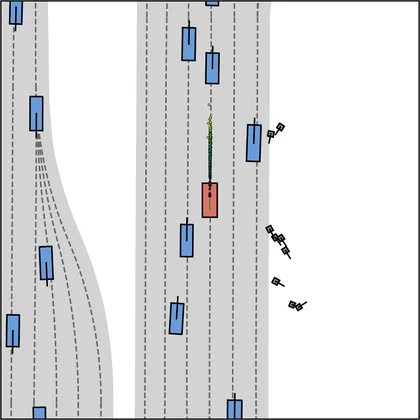 |  |
| FlowR2A (ours) | 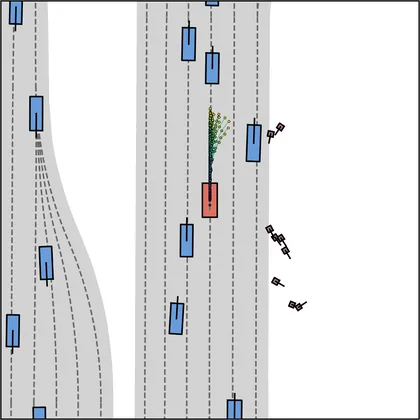 |  |
| DiffusionDrive | 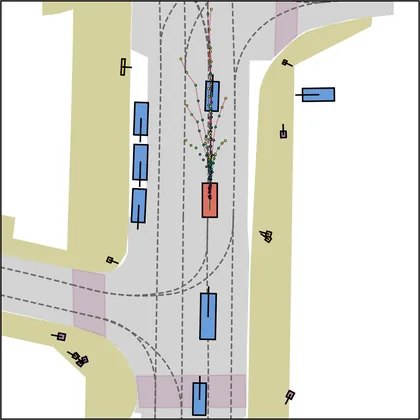 |  |
|---|---|---|
| DiffusionDriveV2 | 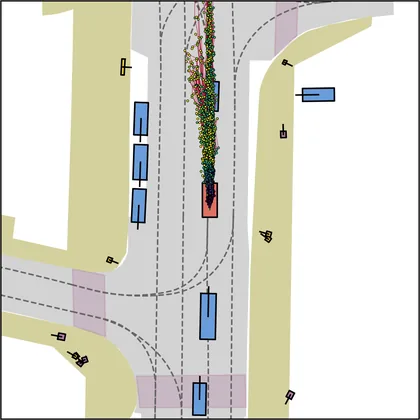 |  |
| iPad | 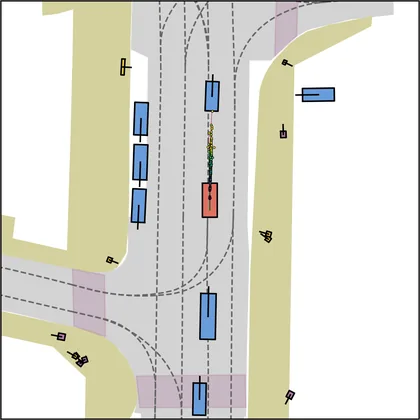 |  |
| FlowR2A (ours) | 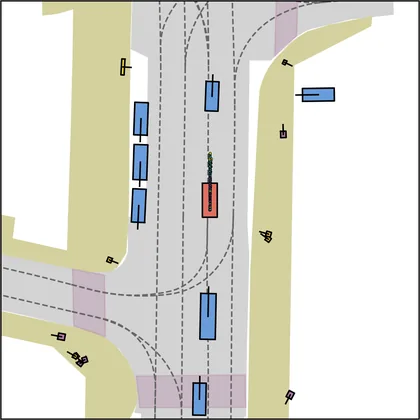 |  |
| DiffusionDrive | 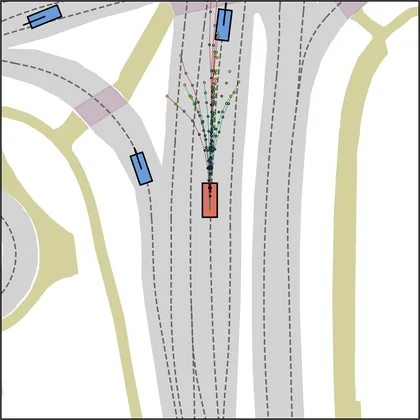 |  |
|---|---|---|
| DiffusionDriveV2 | 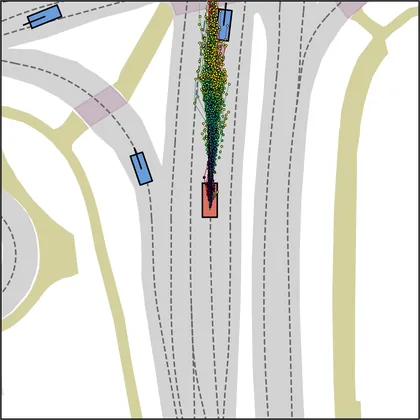 |  |
| iPad | 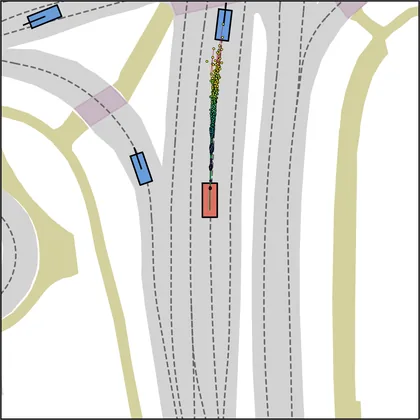 |  |
| FlowR2A (ours) | 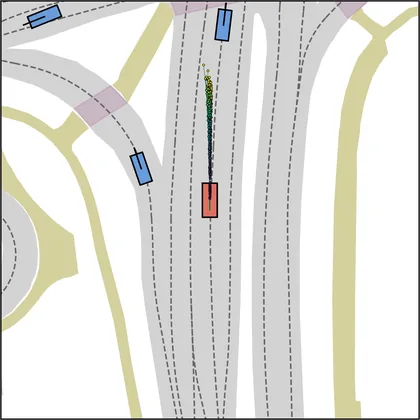 |  |
| DiffusionDrive | 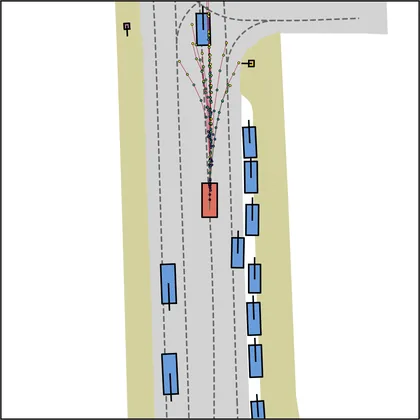 |  |
|---|---|---|
| DiffusionDriveV2 | 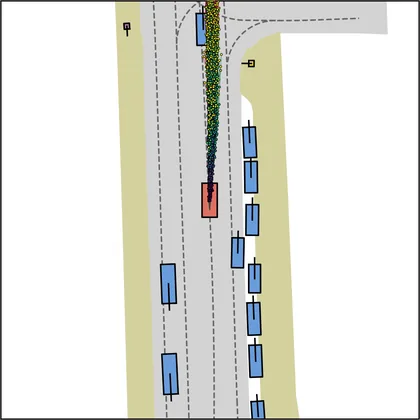 |  |
| iPad | 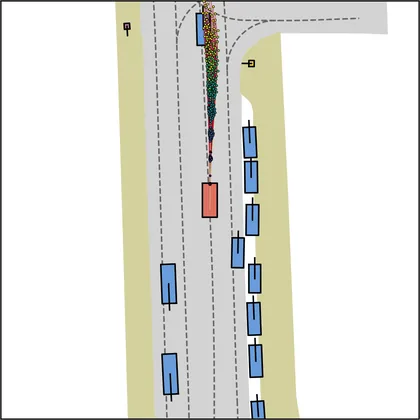 |  |
| FlowR2A (ours) | 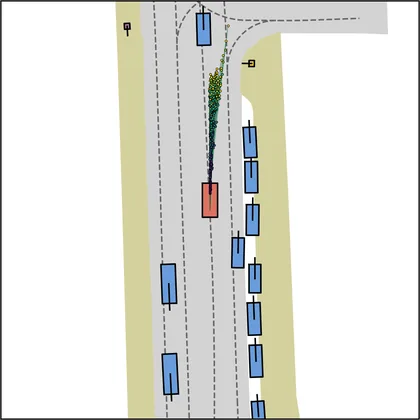 |  |
| DiffusionDrive | 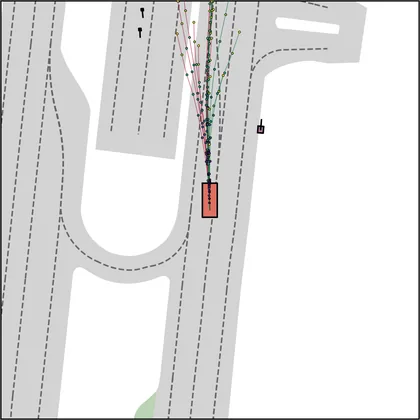 |  |
|---|---|---|
| DiffusionDriveV2 |  |  |
| iPad | 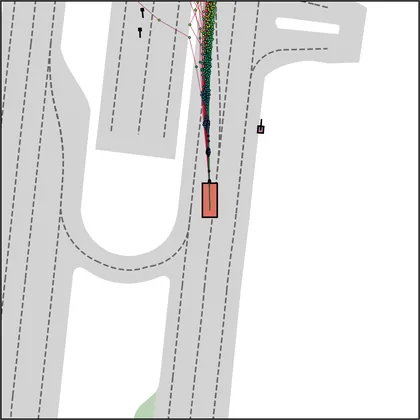 |  |
| FlowR2A (ours) | 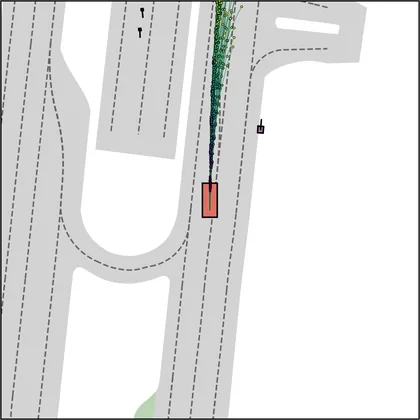 |  |
| DiffusionDrive | 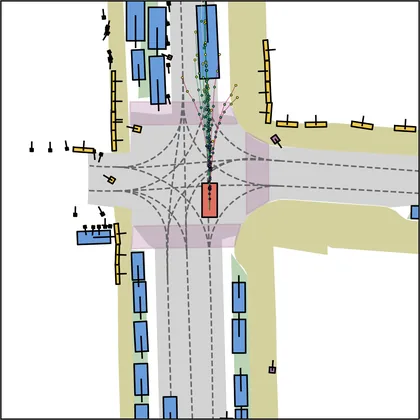 |  |
|---|---|---|
| DiffusionDriveV2 | 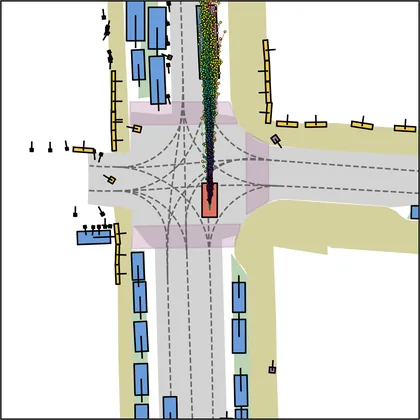 |  |
| iPad | 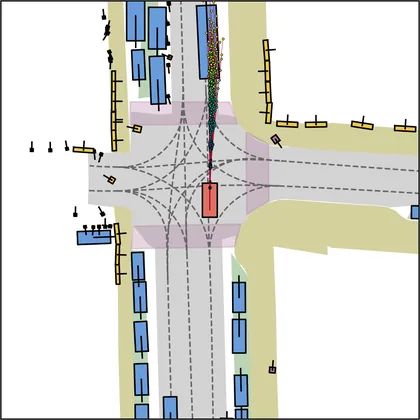 |  |
| FlowR2A (ours) | 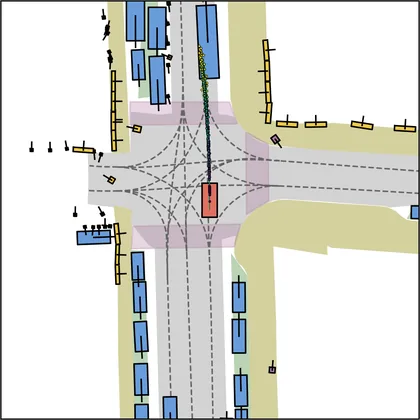 |  |
| DiffusionDrive | 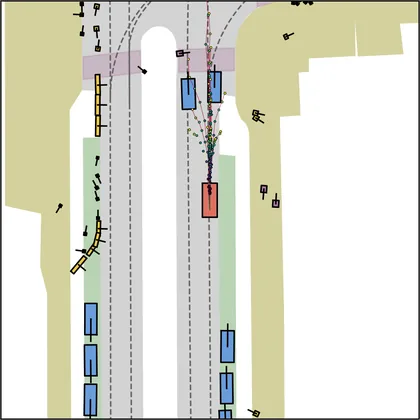 |  |
|---|---|---|
| DiffusionDriveV2 | 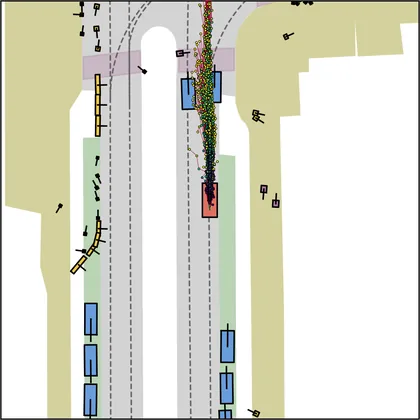 |  |
| iPad | 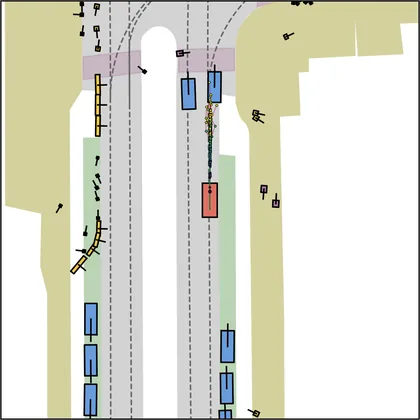 |  |
| FlowR2A (ours) | 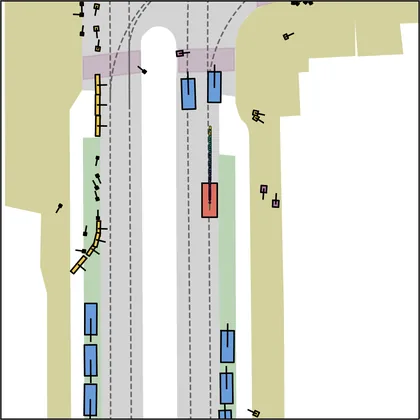 |  |
| DiffusionDrive | 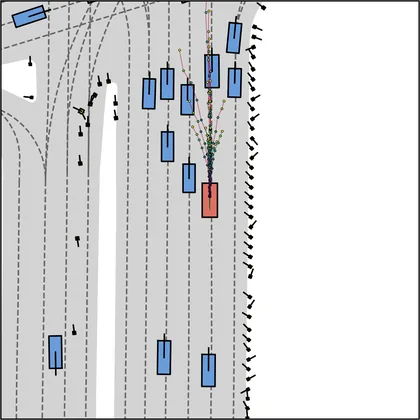 |  |
|---|---|---|
| DiffusionDriveV2 | 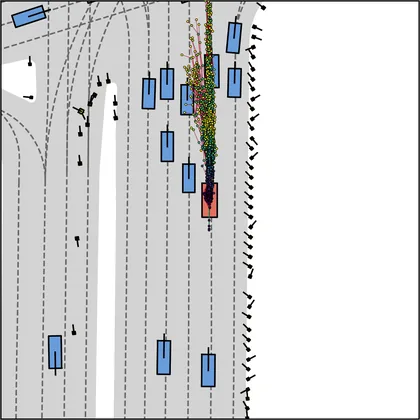 |  |
| iPad | 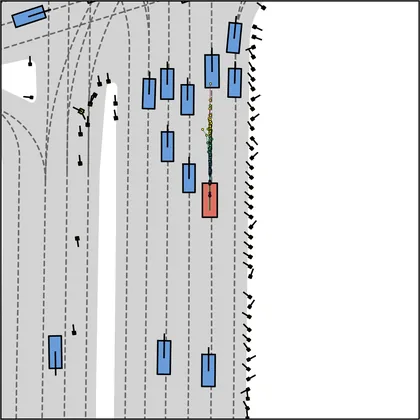 |  |
| FlowR2A (ours) | 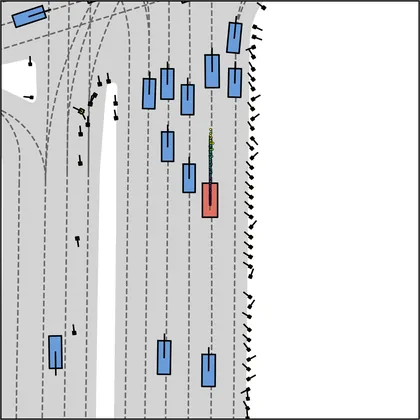 |  |
| DiffusionDrive | 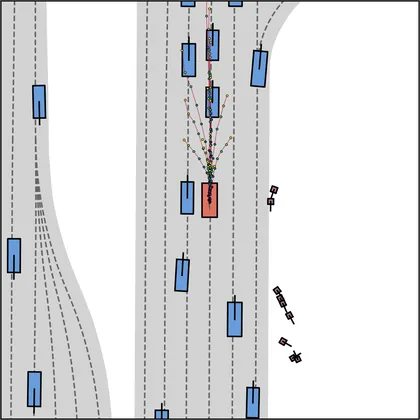 |  |
|---|---|---|
| DiffusionDriveV2 | 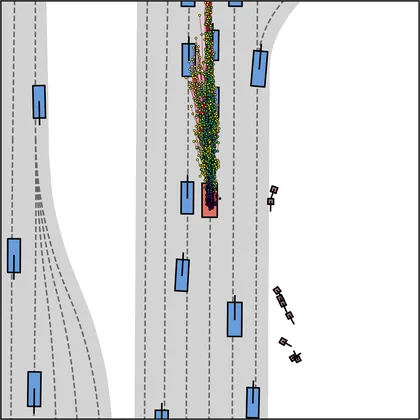 |  |
| iPad | 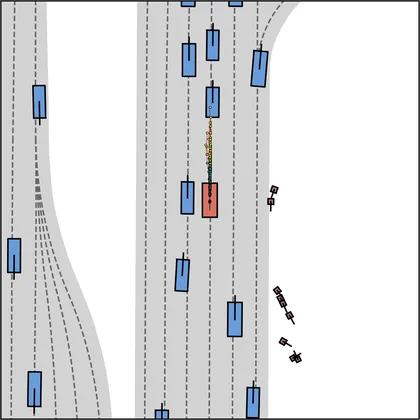 |  |
| FlowR2A (ours) | 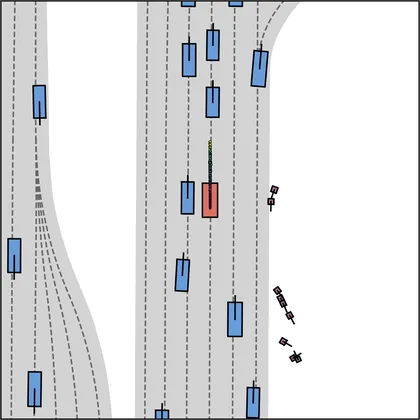 |  |
| DiffusionDrive | 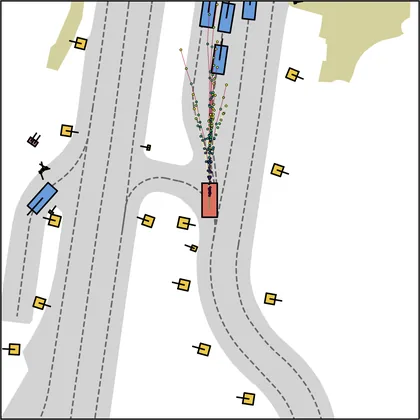 |  |
|---|---|---|
| DiffusionDriveV2 | 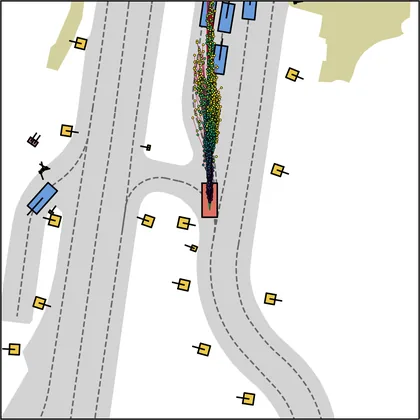 |  |
| iPad | 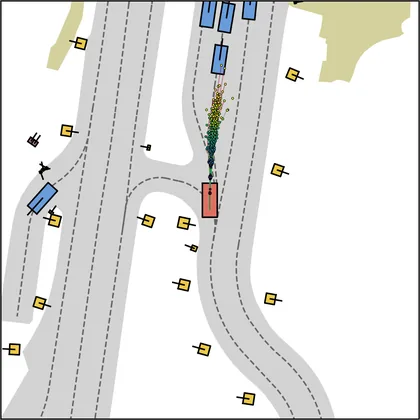 |  |
| FlowR2A (ours) | 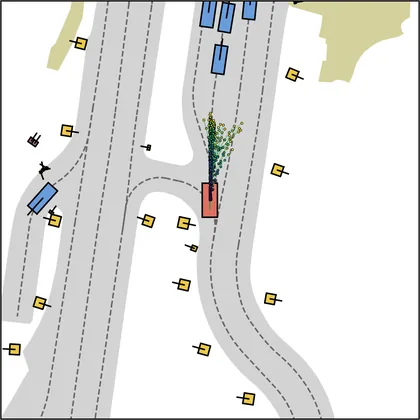 |  |
| DiffusionDrive | 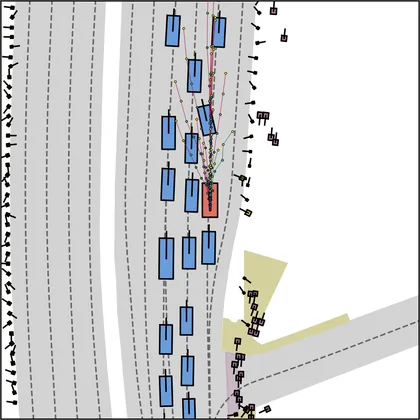 |  |
|---|---|---|
| DiffusionDriveV2 | 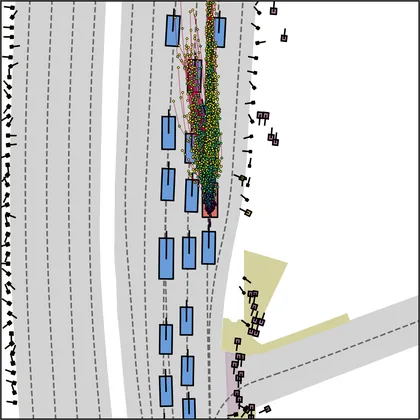 |  |
| iPad | 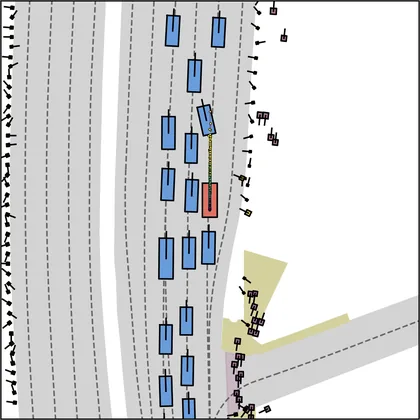 |  |
| FlowR2A (ours) | 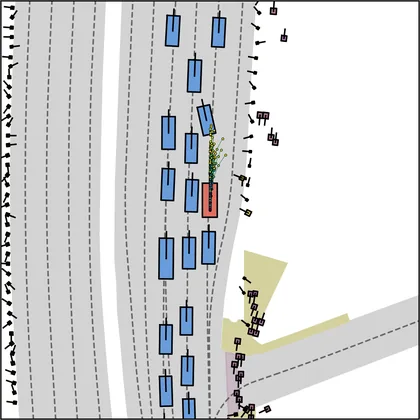 |  |
| DiffusionDrive | 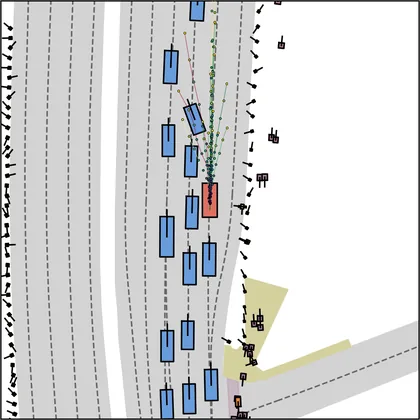 |  |
|---|---|---|
| DiffusionDriveV2 | 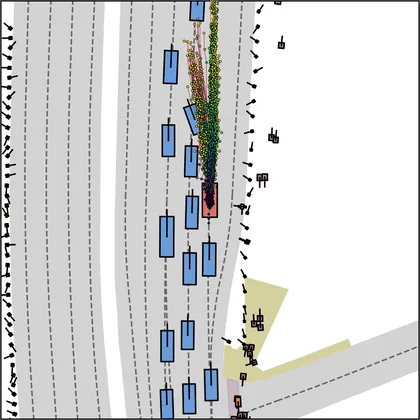 |  |
| iPad | 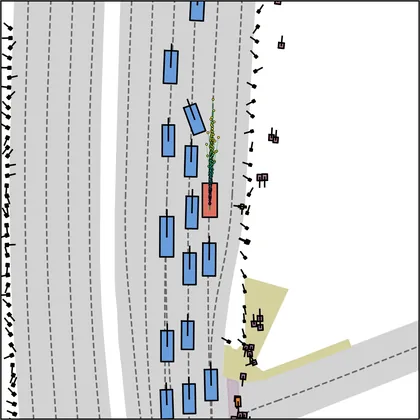 |  |
| FlowR2A (ours) | 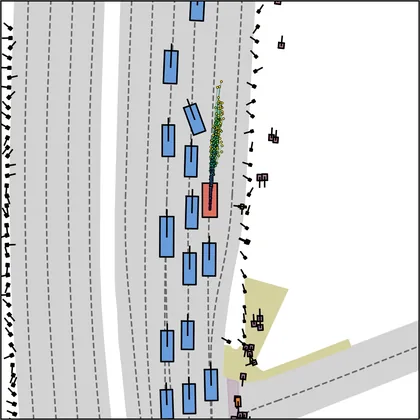 |  |
| DiffusionDrive | 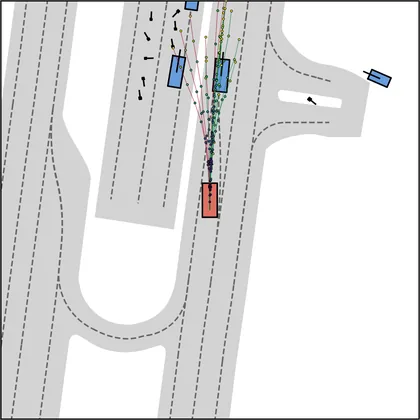 |  |
|---|---|---|
| DiffusionDriveV2 | 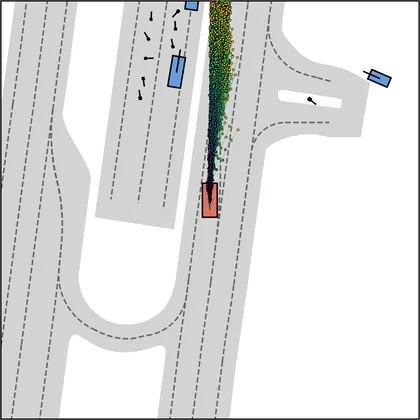 |  |
| iPad | 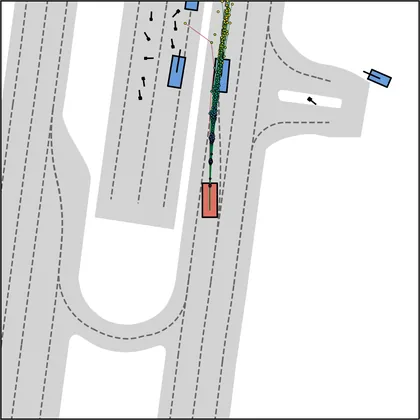 |  |
| FlowR2A (ours) | 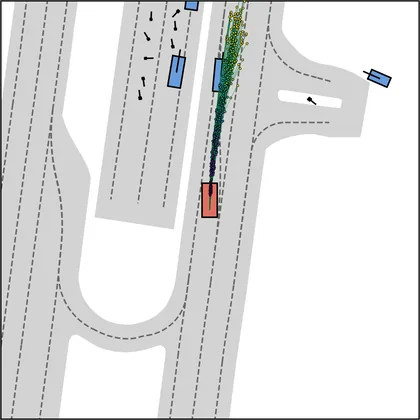 |  |
| DiffusionDrive | 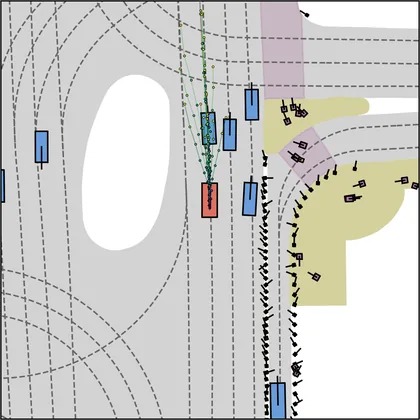 |  |
|---|---|---|
| DiffusionDriveV2 | 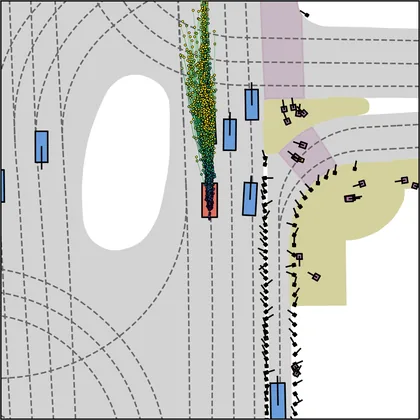 |  |
| iPad | 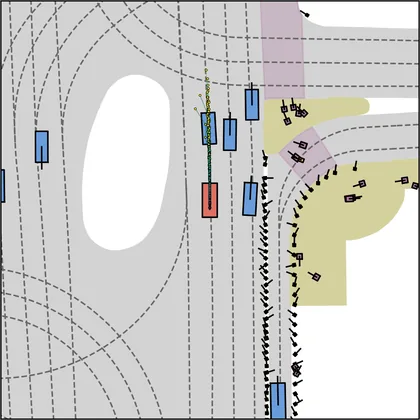 |  |
| FlowR2A (ours) | 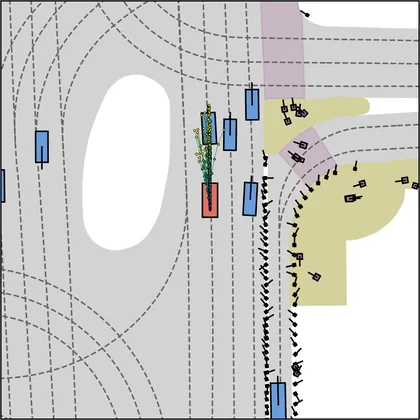 |  |
| DiffusionDrive | 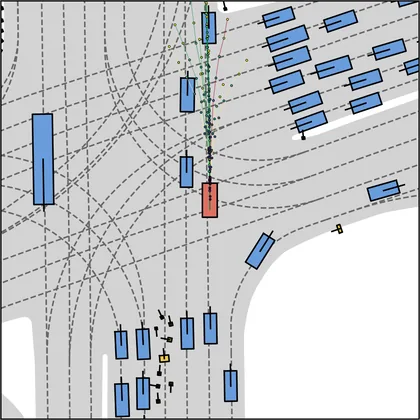 |  |
|---|---|---|
| DiffusionDriveV2 | 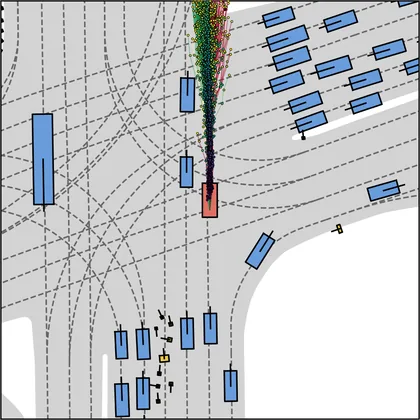 |  |
| iPad | 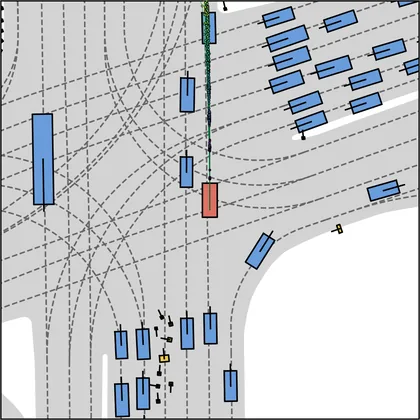 |  |
| FlowR2A (ours) | 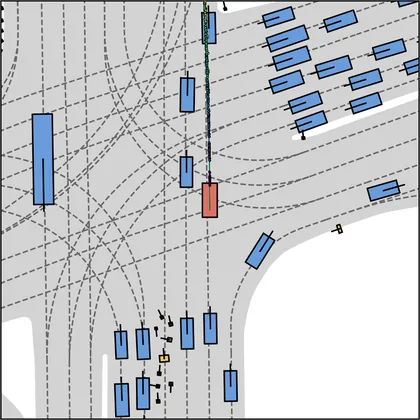 |  |
| DiffusionDrive | 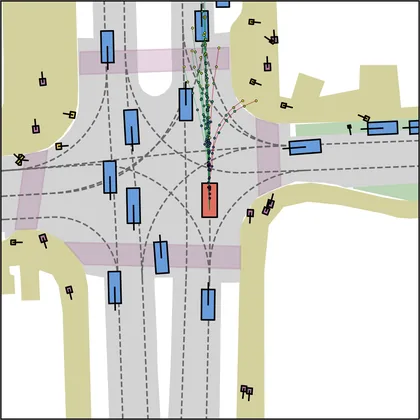 |  |
|---|---|---|
| DiffusionDriveV2 | 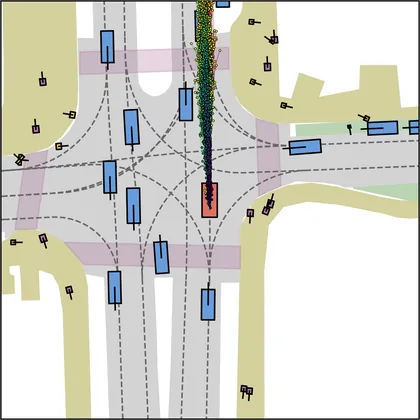 |  |
| iPad | 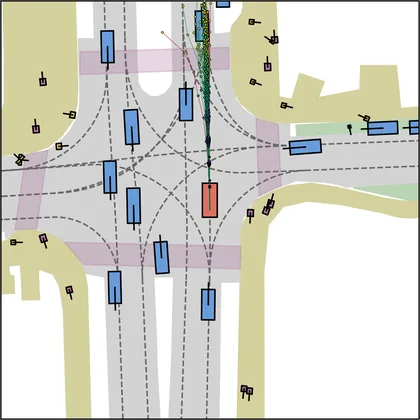 |  |
| FlowR2A (ours) | 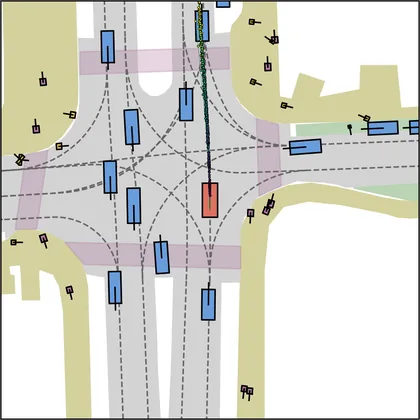 |  |
| DiffusionDrive | 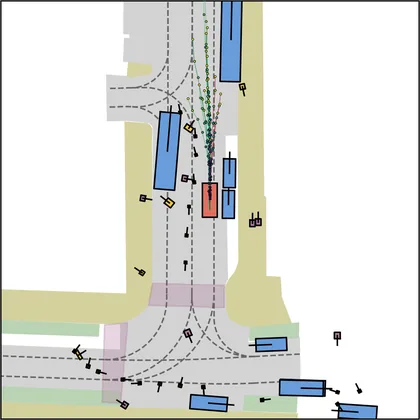 |  |
|---|---|---|
| DiffusionDriveV2 | 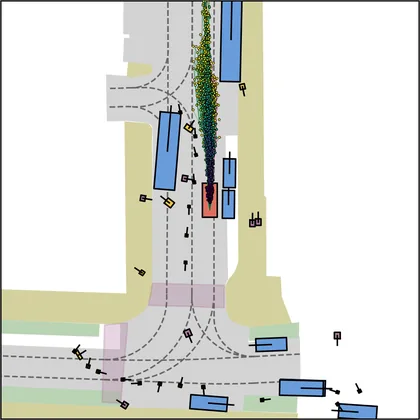 |  |
| iPad | 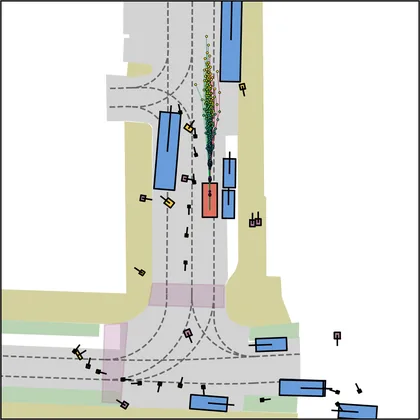 |  |
| FlowR2A (ours) | 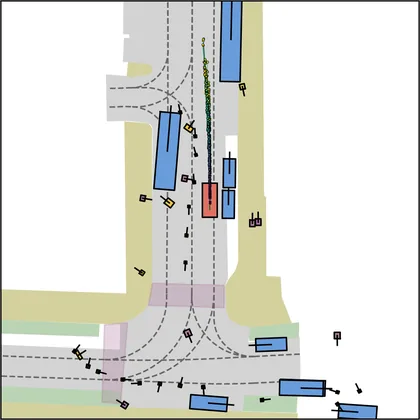 |  |
| DiffusionDrive | 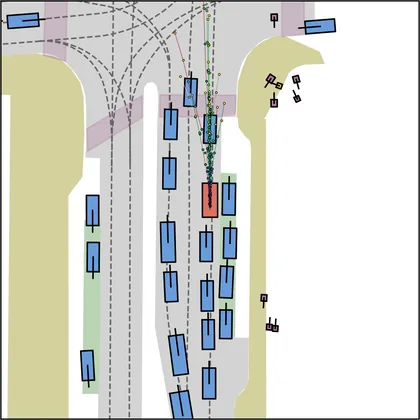 |  |
|---|---|---|
| DiffusionDriveV2 | 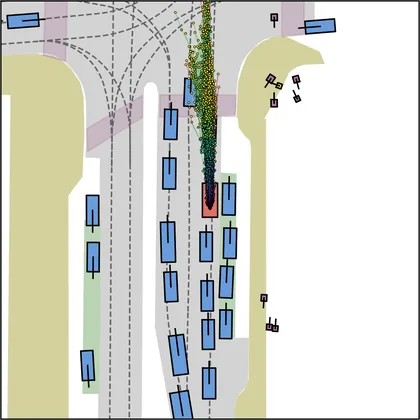 |  |
| iPad | 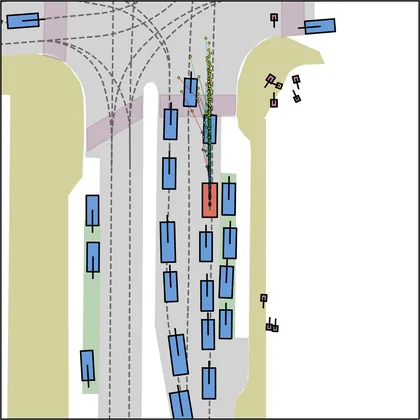 |  |
| FlowR2A (ours) | 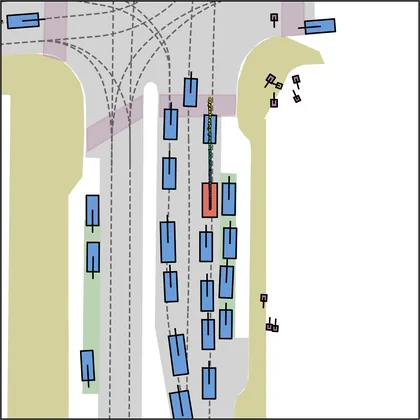 |  |
| DiffusionDrive | 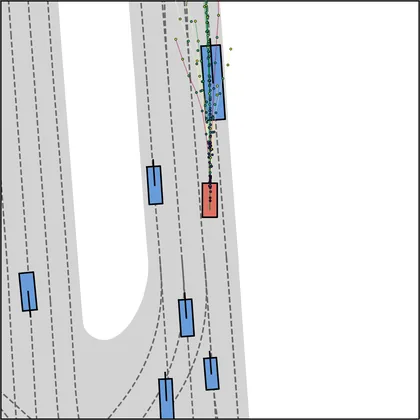 |  |
|---|---|---|
| DiffusionDriveV2 | 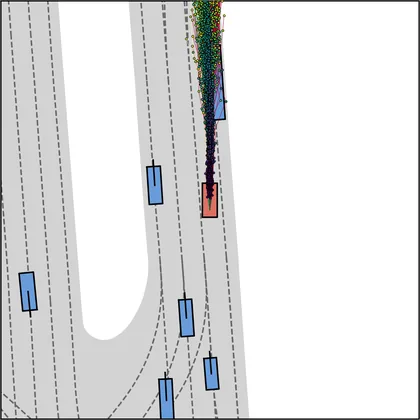 |  |
| iPad | 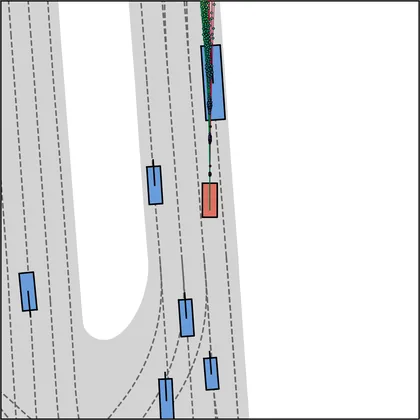 |  |
| FlowR2A (ours) | 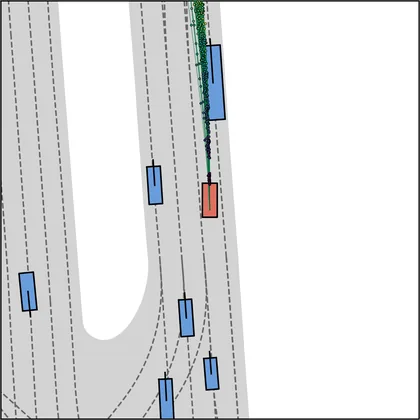 |  |
| DiffusionDrive | 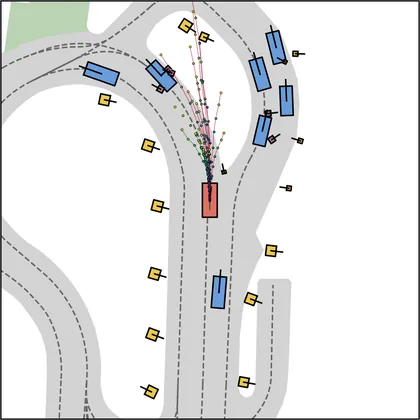 |  |
|---|---|---|
| DiffusionDriveV2 | 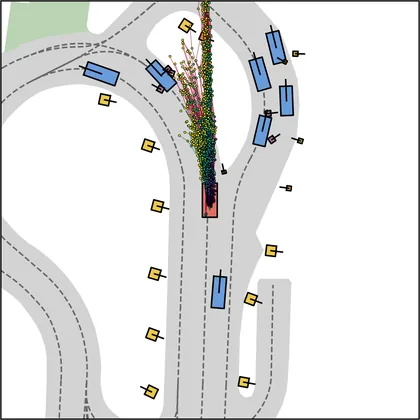 |  |
| iPad | 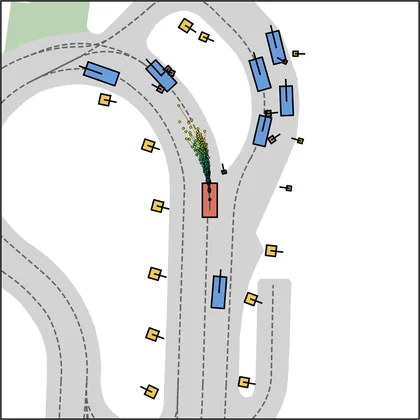 |  |
| FlowR2A (ours) | 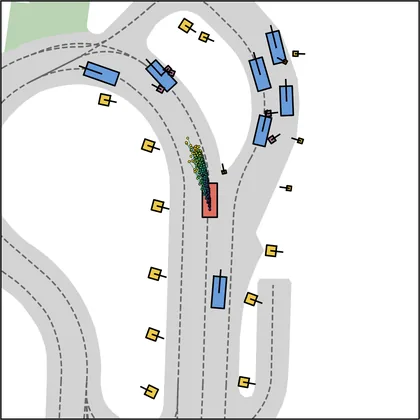 |  |
| DiffusionDrive | 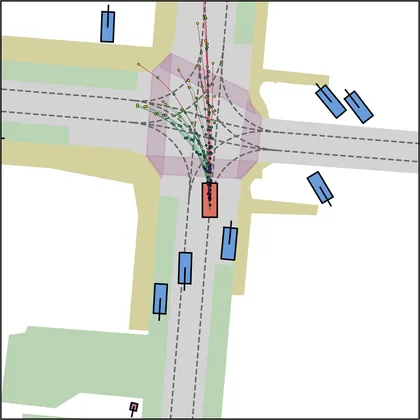 |  |
|---|---|---|
| DiffusionDriveV2 | 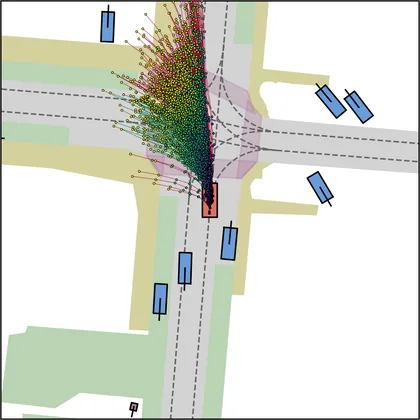 |  |
| iPad | 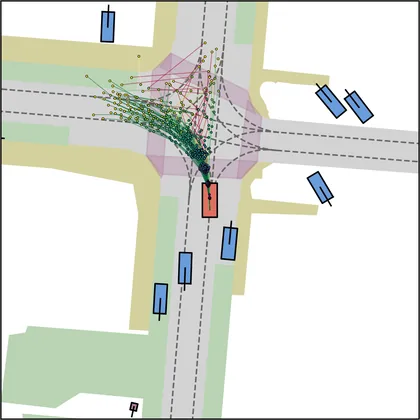 |  |
| FlowR2A (ours) | 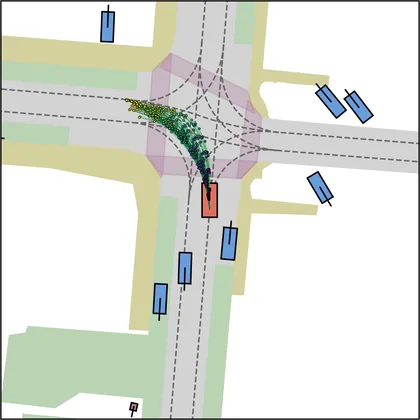 |  |
| DiffusionDrive | 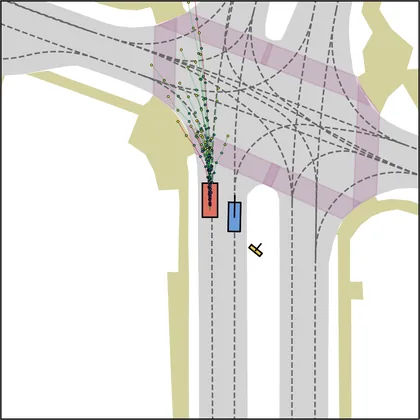 |  |
|---|---|---|
| DiffusionDriveV2 | 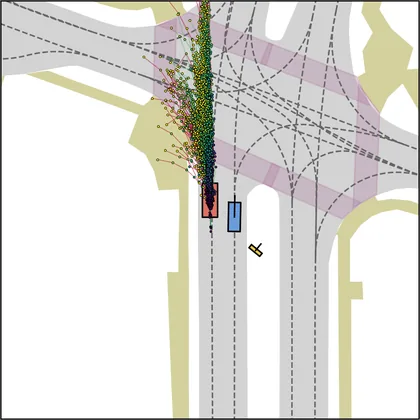 |  |
| iPad | 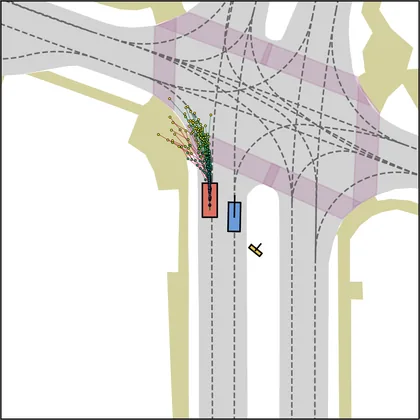 |  |
| FlowR2A (ours) | 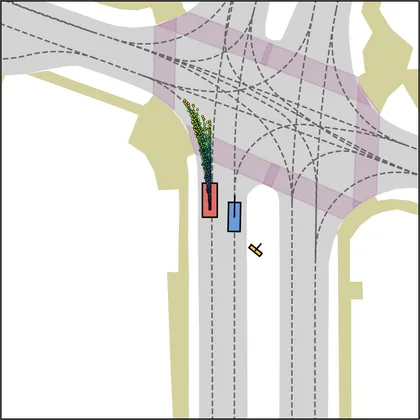 |  |
| DiffusionDrive | 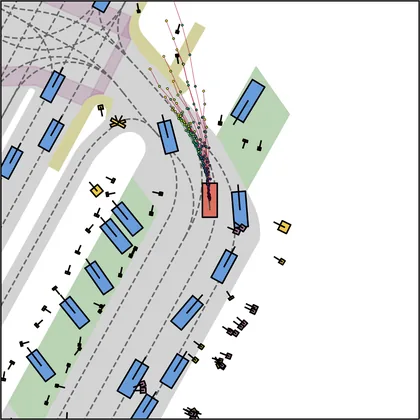 |  |
|---|---|---|
| DiffusionDriveV2 | 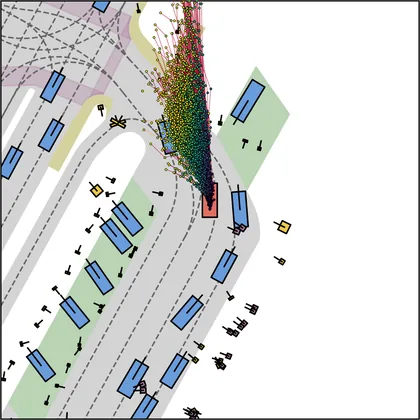 |  |
| iPad | 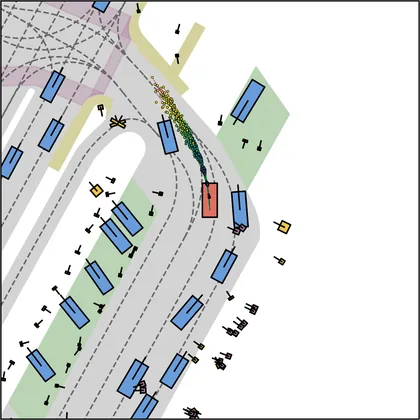 |  |
| FlowR2A (ours) | 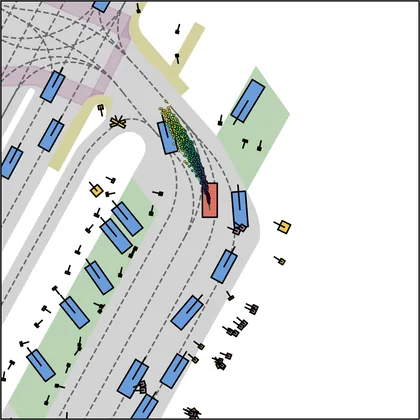 |  |
| DiffusionDrive | 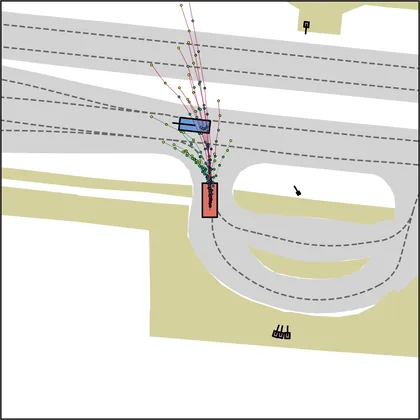 |  |
|---|---|---|
| DiffusionDriveV2 | 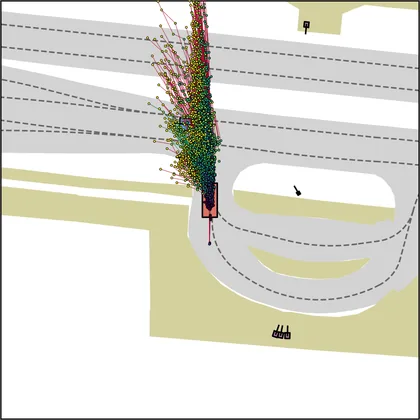 |  |
| iPad | 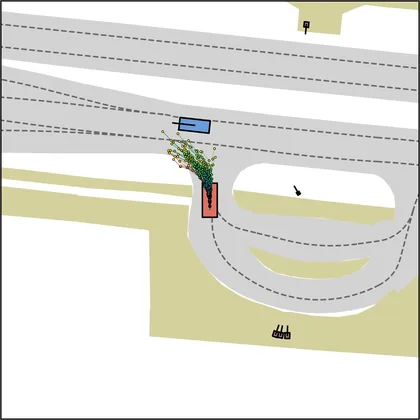 |  |
| FlowR2A (ours) | 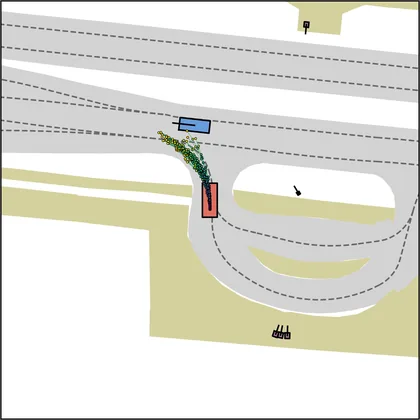 |  |
| DiffusionDrive | 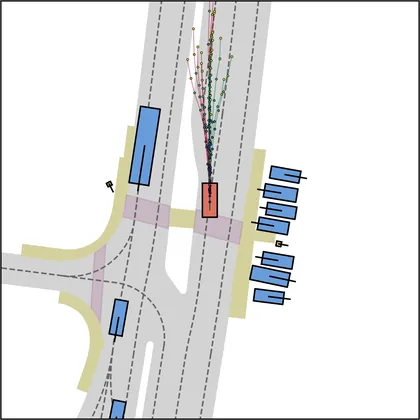 |  |
|---|---|---|
| DiffusionDriveV2 | 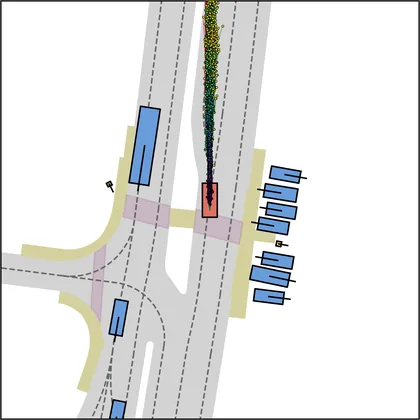 |  |
| iPad | 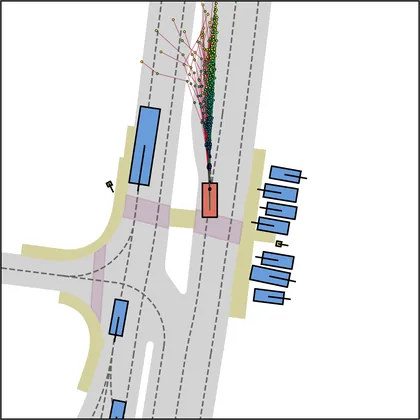 |  |
| FlowR2A (ours) | 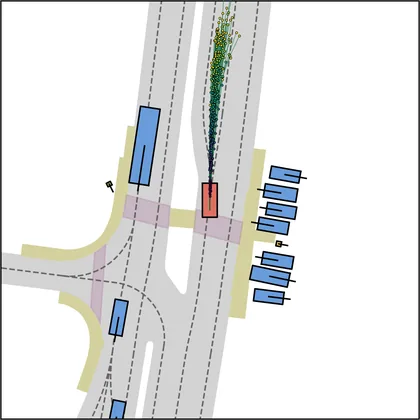 |  |
| DiffusionDrive | 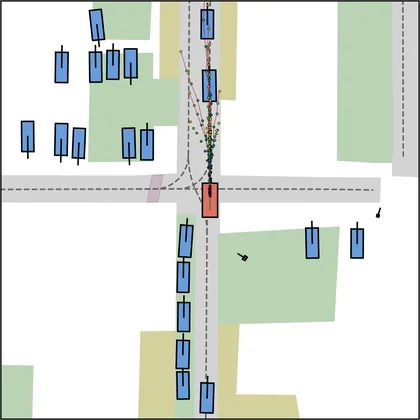 |  |
|---|---|---|
| DiffusionDriveV2 | 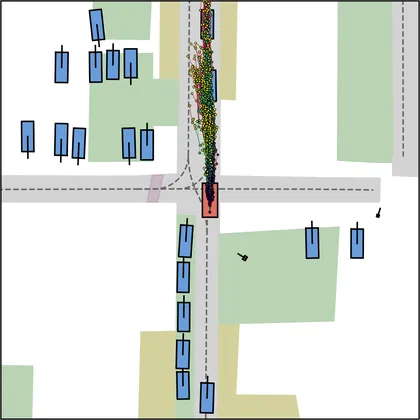 |  |
| iPad | 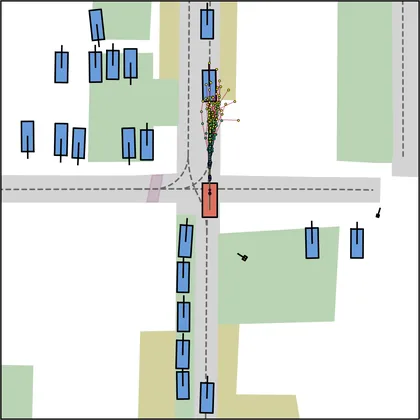 |  |
| FlowR2A (ours) | 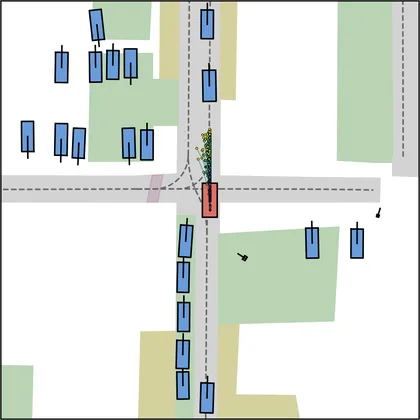 |  |
| DiffusionDrive | 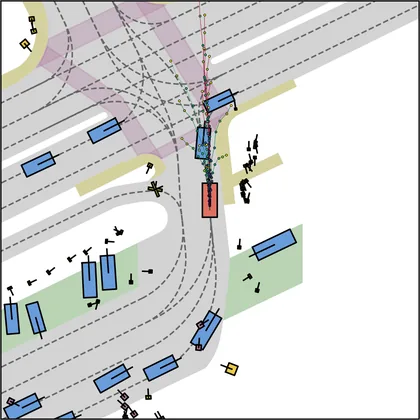 |  |
|---|---|---|
| DiffusionDriveV2 | 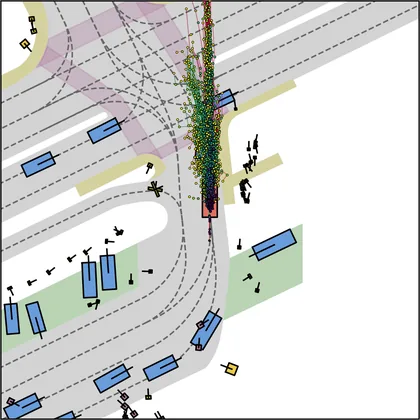 |  |
| iPad | 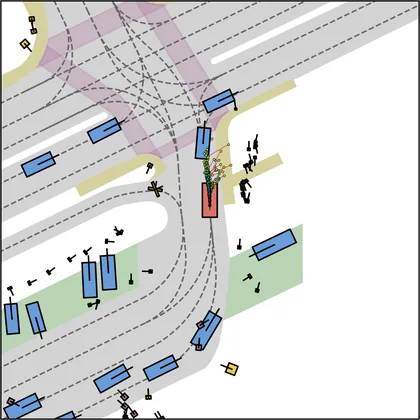 |  |
| FlowR2A (ours) | 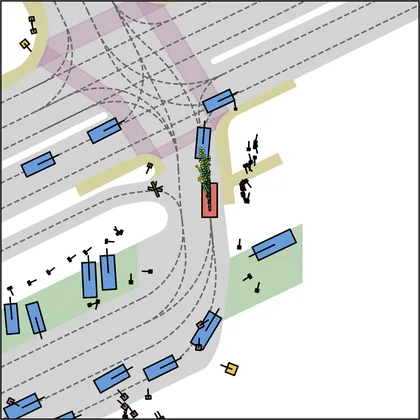 |  |
| DiffusionDrive | 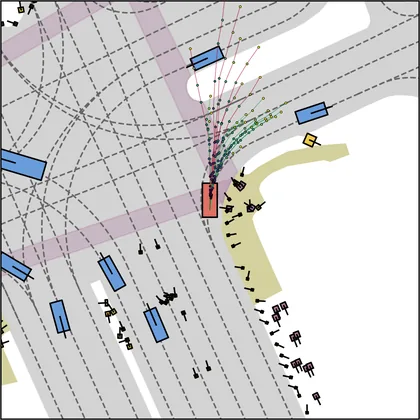 |  |
|---|---|---|
| DiffusionDriveV2 | 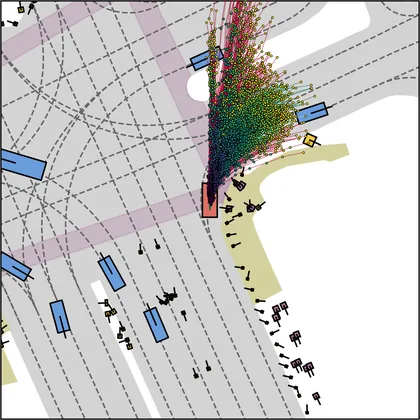 |  |
| iPad | 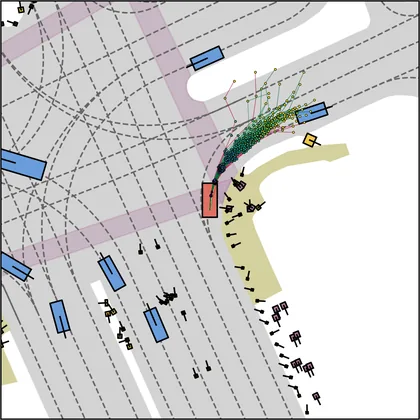 |  |
| FlowR2A (ours) | 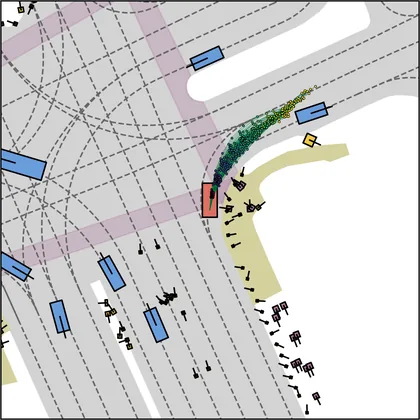 |  |
| DiffusionDrive | 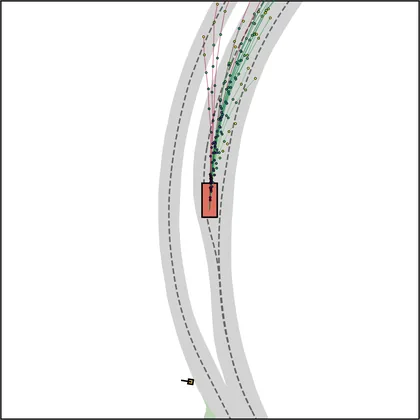 |  |
|---|---|---|
| DiffusionDriveV2 |  |  |
| iPad | 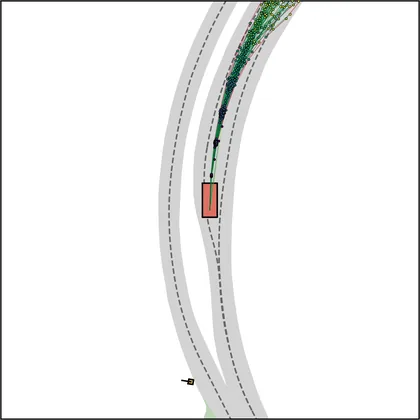 |  |
| FlowR2A (ours) |  |  |
| DiffusionDrive | 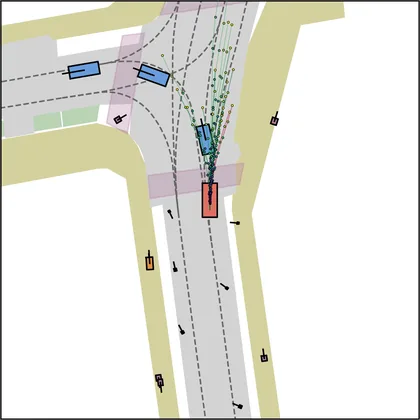 |  |
|---|---|---|
| DiffusionDriveV2 | 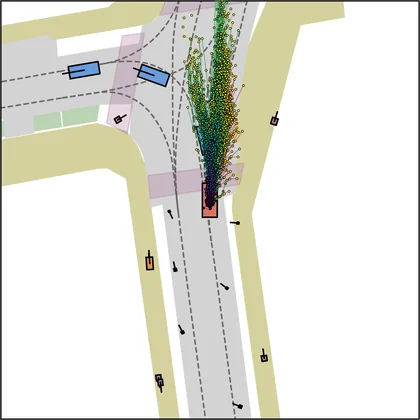 |  |
| iPad | 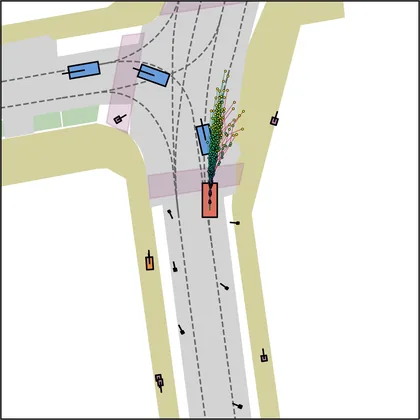 |  |
| FlowR2A (ours) | 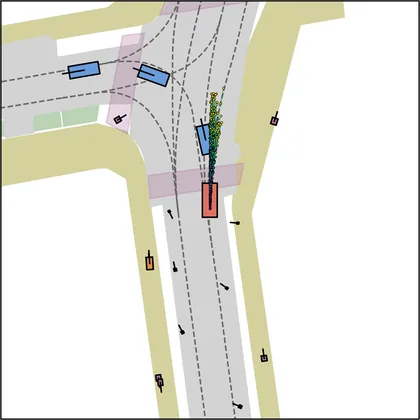 |  |
| DiffusionDrive | 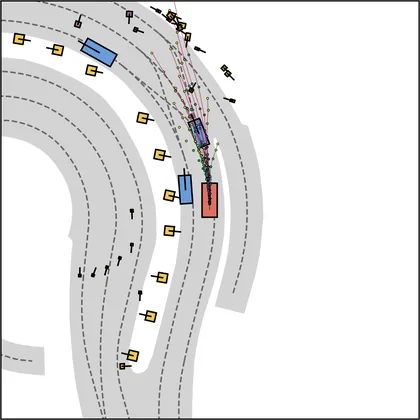 |  |
|---|---|---|
| DiffusionDriveV2 | 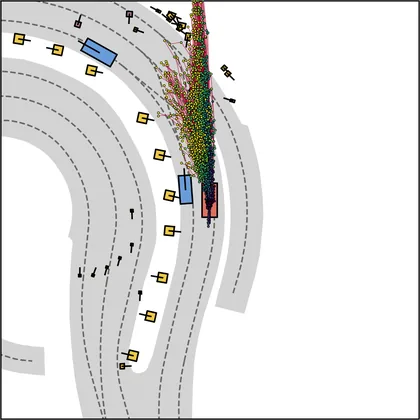 |  |
| iPad | 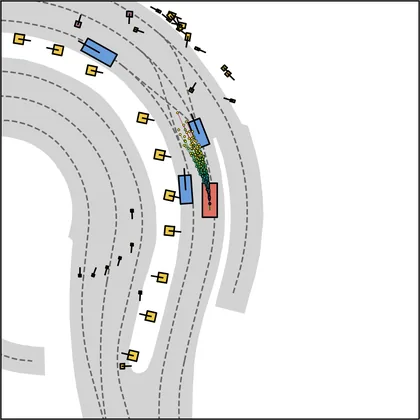 |  |
| FlowR2A (ours) | 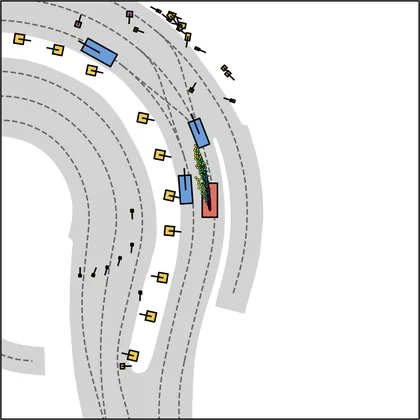 |  |
| DiffusionDrive | 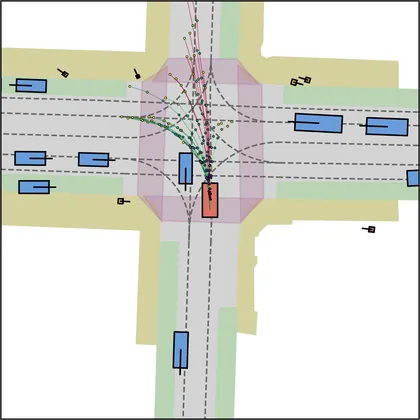 |  |
|---|---|---|
| DiffusionDriveV2 | 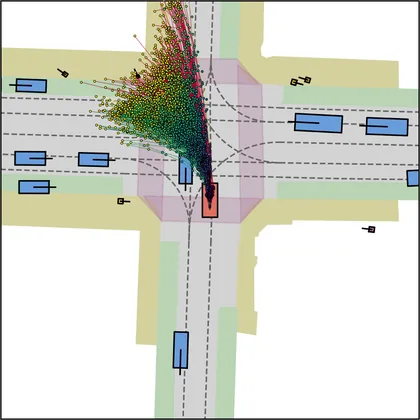 |  |
| iPad | 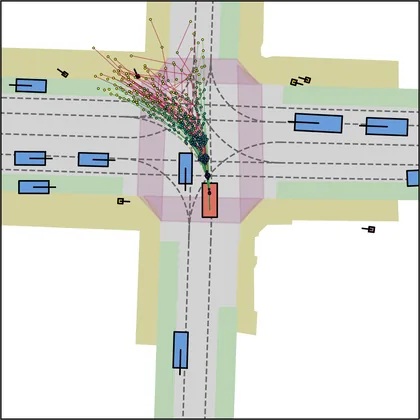 |  |
| FlowR2A (ours) | 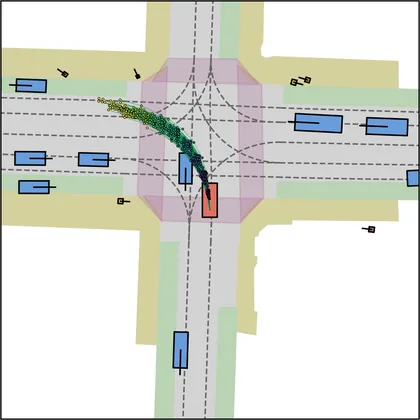 |  |
| DiffusionDrive | 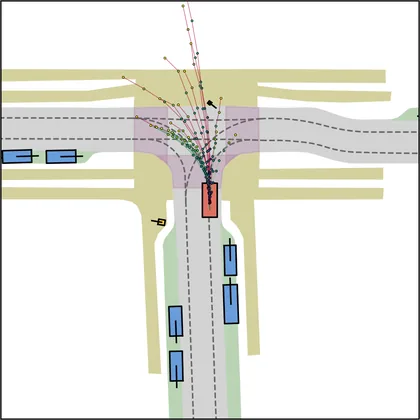 |  |
|---|---|---|
| DiffusionDriveV2 | 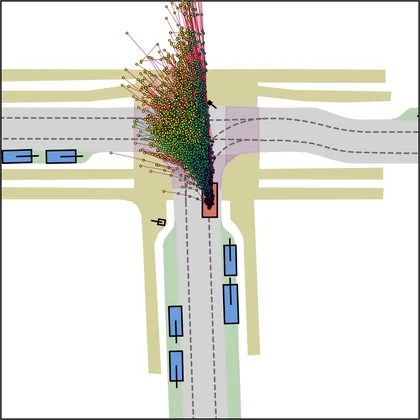 |  |
| iPad | 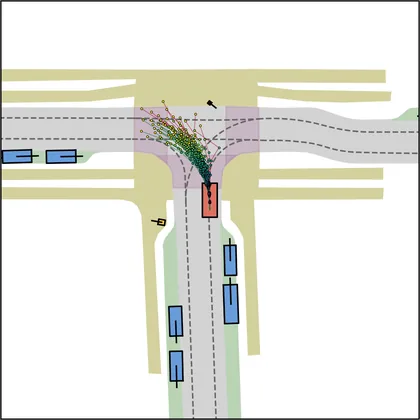 |  |
| FlowR2A (ours) | 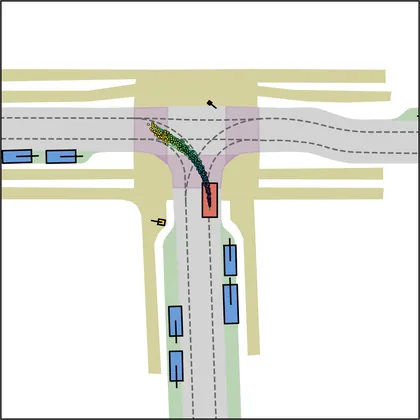 |  |
| DiffusionDrive | 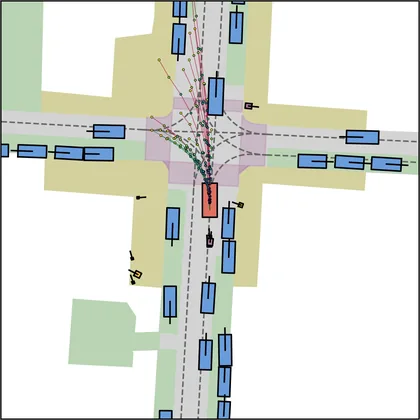 |  |
|---|---|---|
| DiffusionDriveV2 | 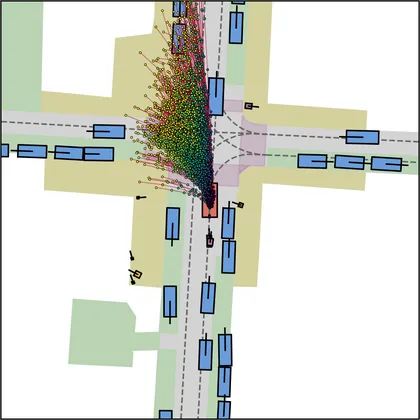 |  |
| iPad | 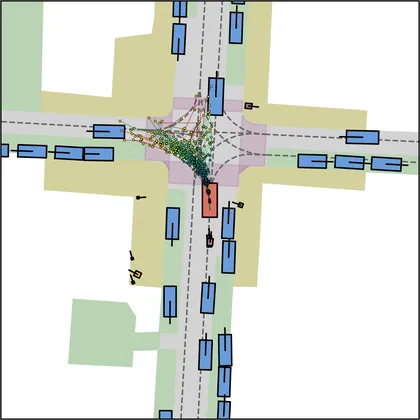 |  |
| FlowR2A (ours) | 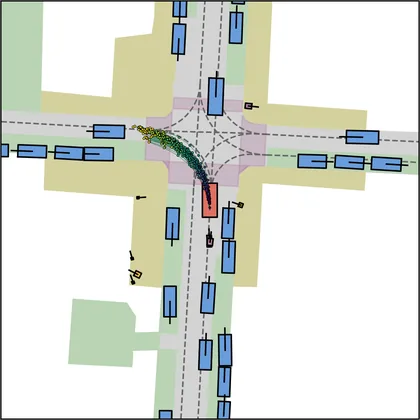 |  |
| DiffusionDrive | 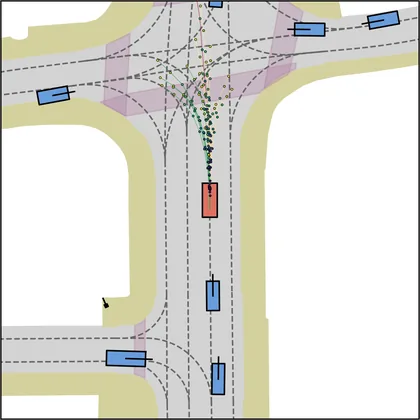 |  |
|---|---|---|
| DiffusionDriveV2 | 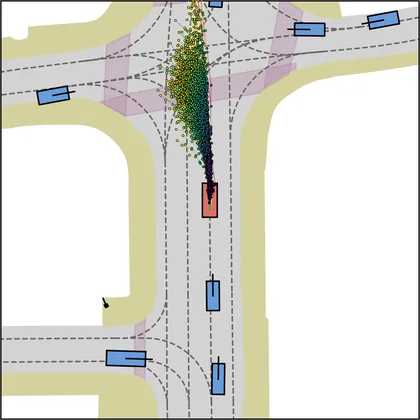 |  |
| iPad | 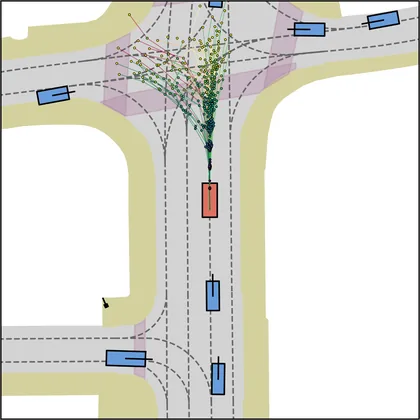 |  |
| FlowR2A (ours) | 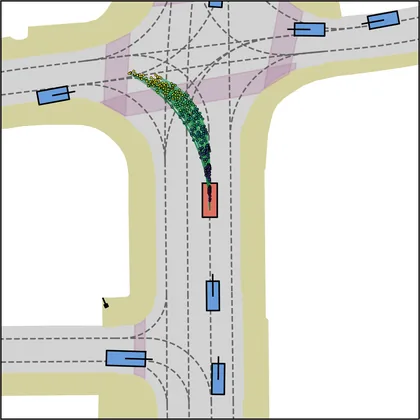 |  |
| DiffusionDrive | 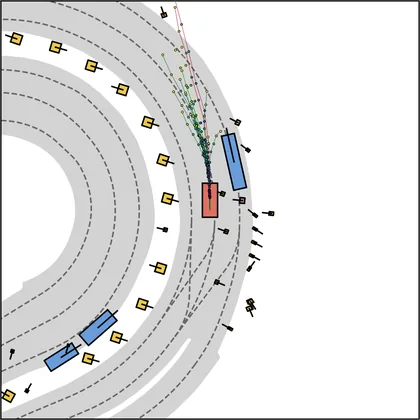 |  |
|---|---|---|
| DiffusionDriveV2 | 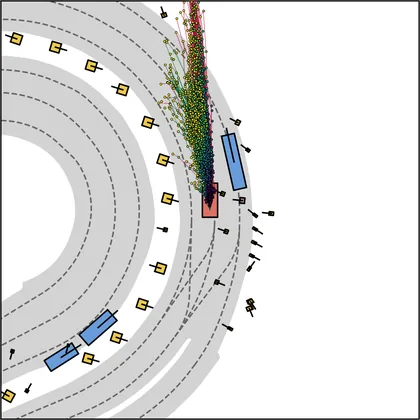 |  |
| iPad | 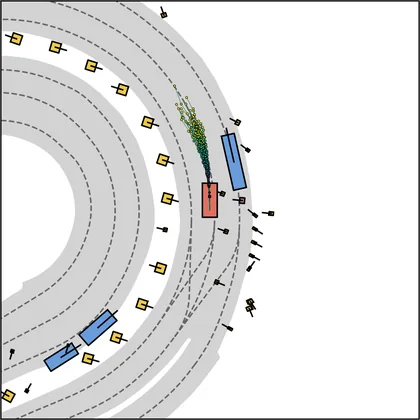 |  |
| FlowR2A (ours) | 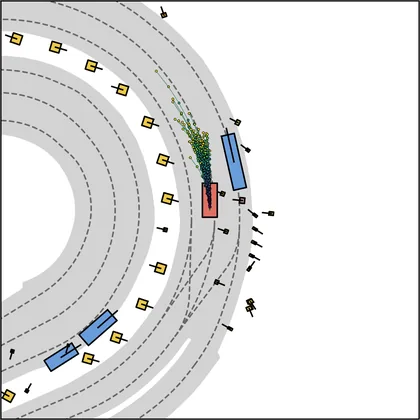 |  |
| DiffusionDrive | 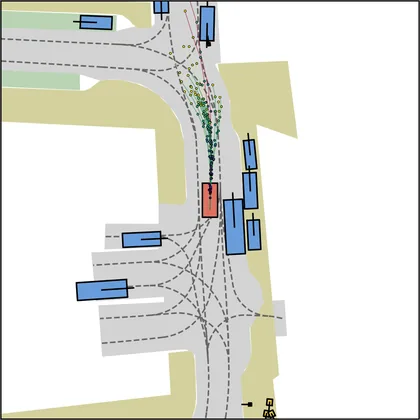 |  |
|---|---|---|
| DiffusionDriveV2 | 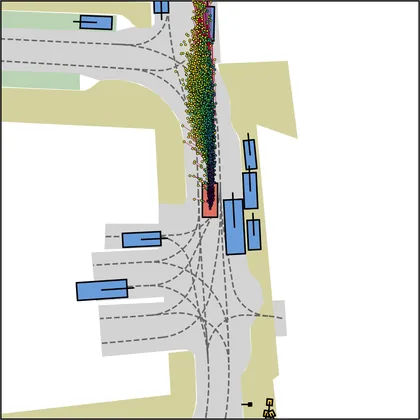 |  |
| iPad | 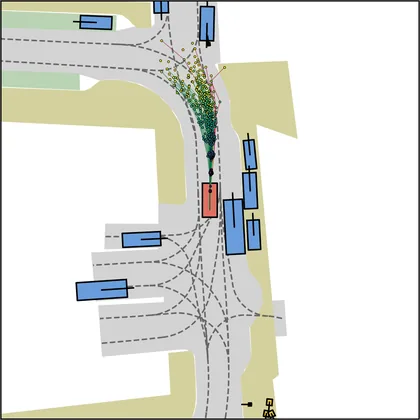 |  |
| FlowR2A (ours) | 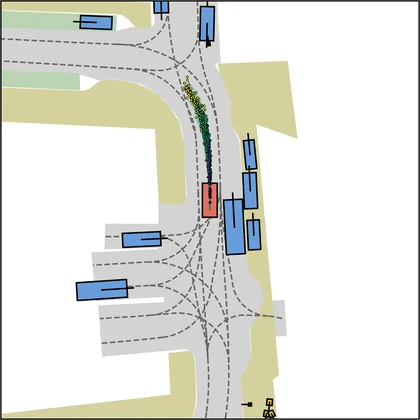 |  |
| DiffusionDrive | 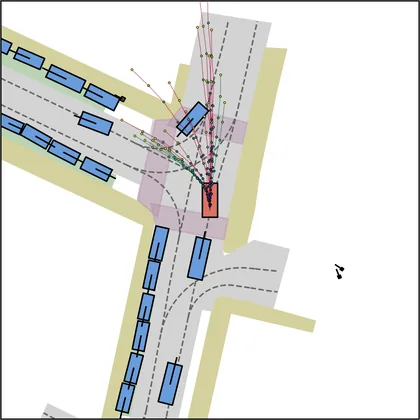 |  |
|---|---|---|
| DiffusionDriveV2 | 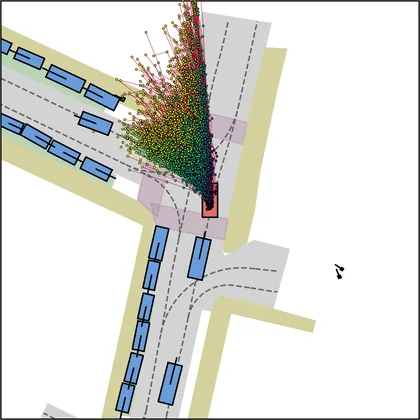 |  |
| iPad | 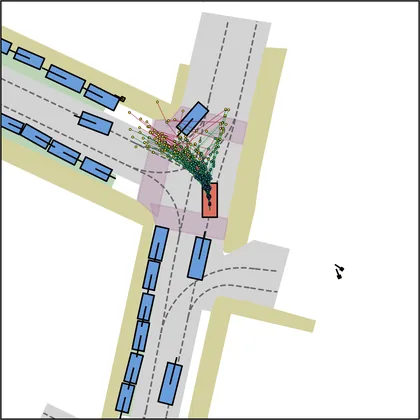 |  |
| FlowR2A (ours) | 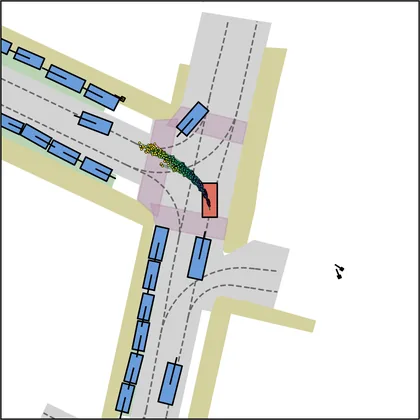 |  |
| DiffusionDrive | 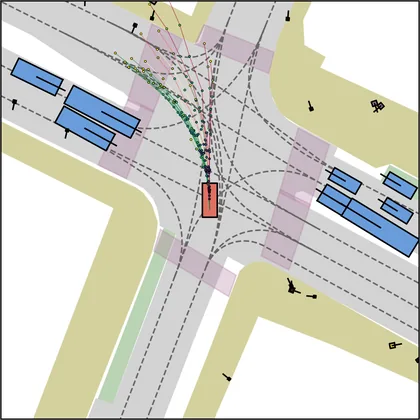 |  |
|---|---|---|
| DiffusionDriveV2 | 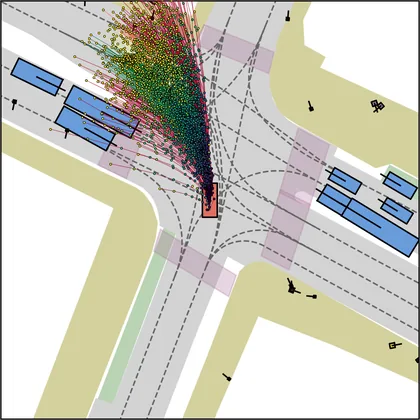 |  |
| iPad | 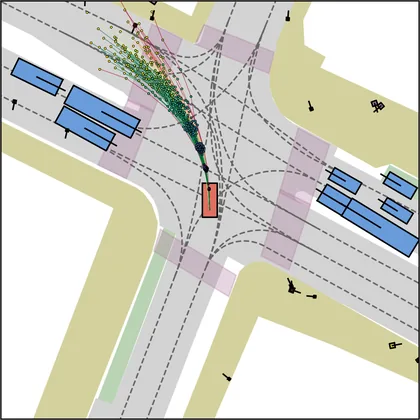 |  |
| FlowR2A (ours) | 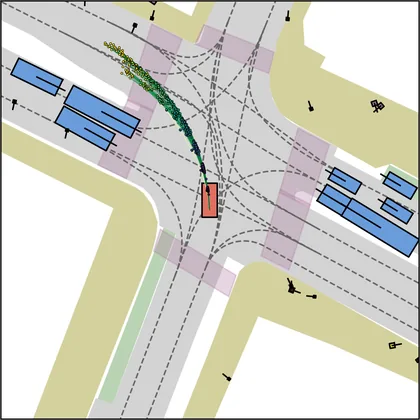 |  |
| DiffusionDrive | 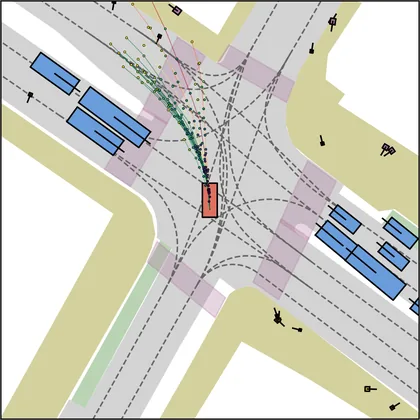 |  |
|---|---|---|
| DiffusionDriveV2 | 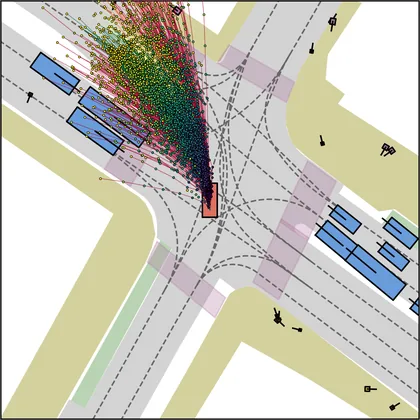 |  |
| iPad | 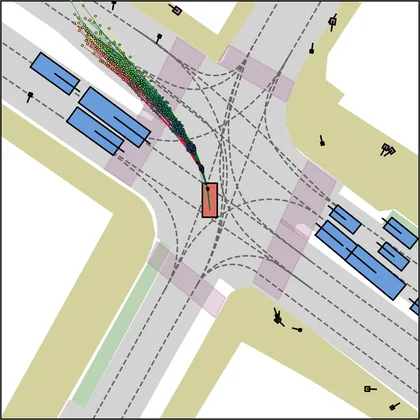 |  |
| FlowR2A (ours) | 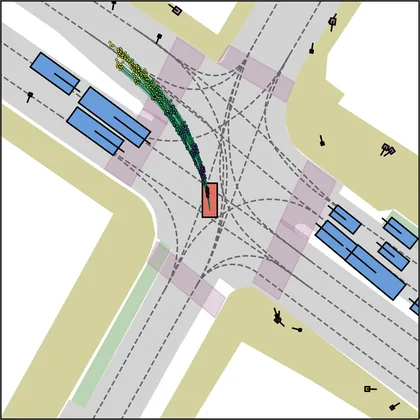 |  |
| DiffusionDrive |  |  |
|---|---|---|
| DiffusionDriveV2 | 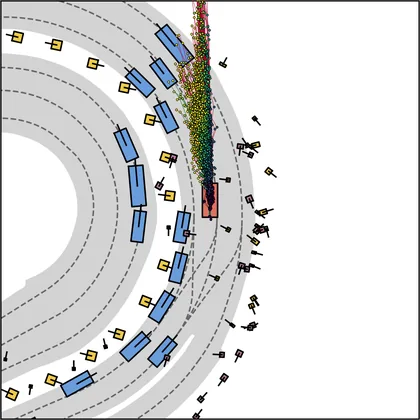 |  |
| iPad | 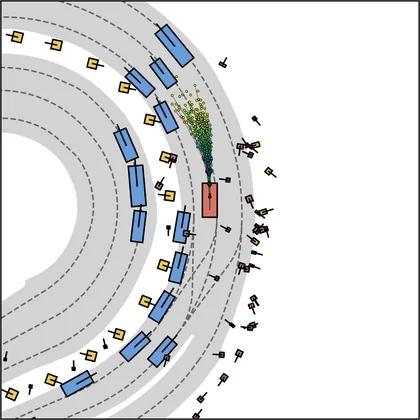 |  |
| FlowR2A (ours) | 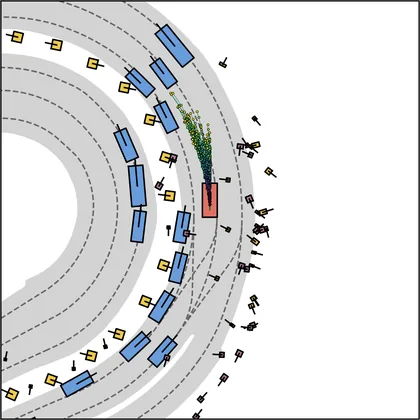 |  |
| DiffusionDrive | 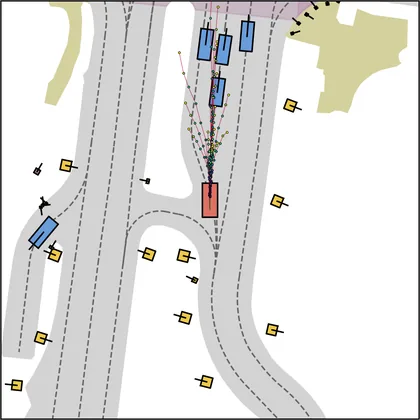 |  |
|---|---|---|
| DiffusionDriveV2 | 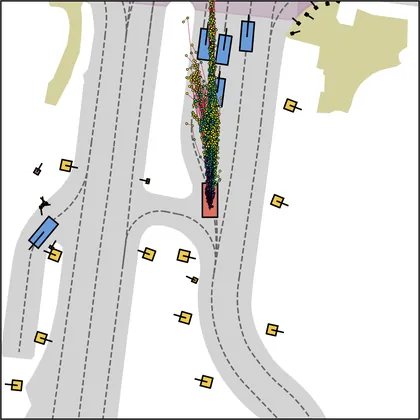 |  |
| iPad | 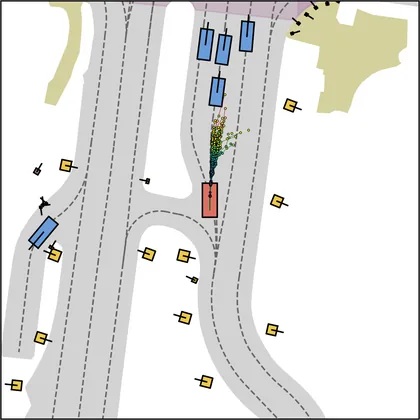 |  |
| FlowR2A (ours) | 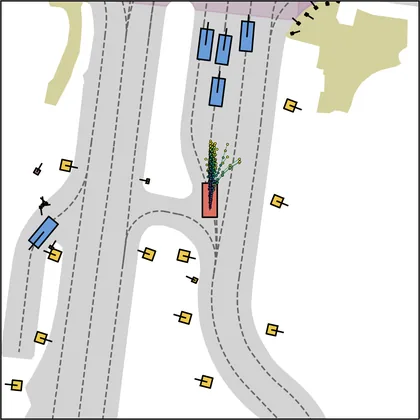 |  |
| DiffusionDrive | 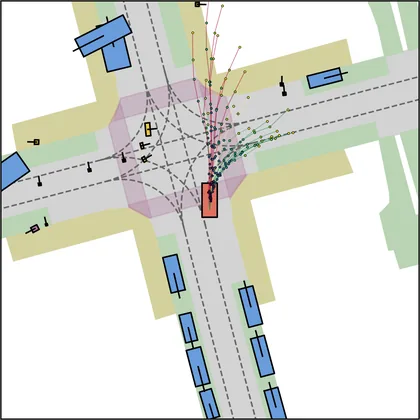 |  |
|---|---|---|
| DiffusionDriveV2 | 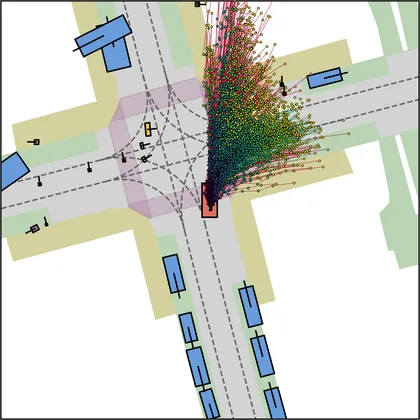 |  |
| iPad | 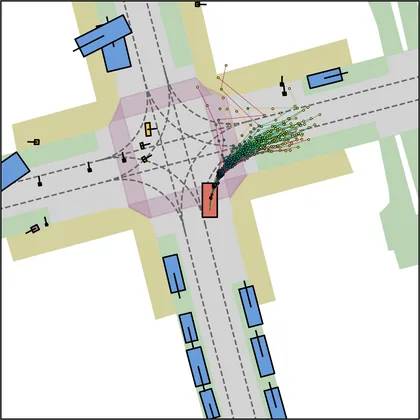 |  |
| FlowR2A (ours) | 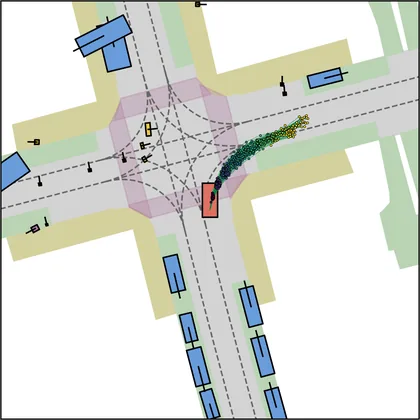 |  |
| DiffusionDrive | 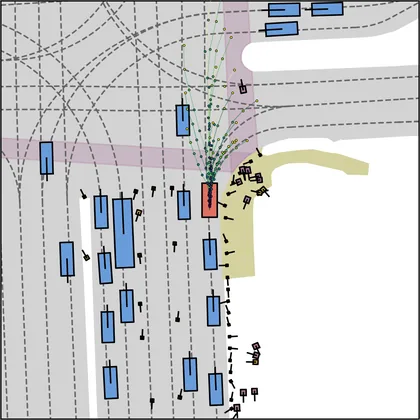 |  |
|---|---|---|
| DiffusionDriveV2 | 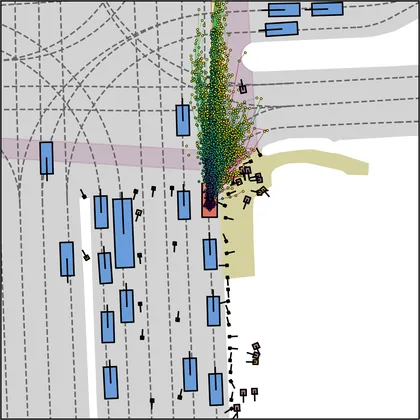 |  |
| iPad | 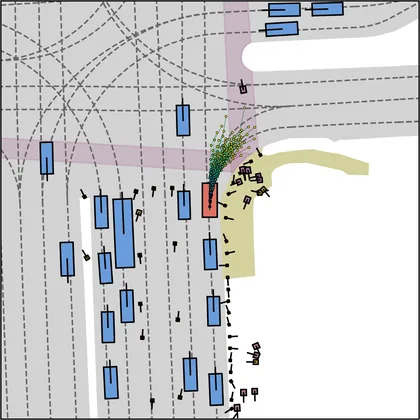 |  |
| FlowR2A (ours) | 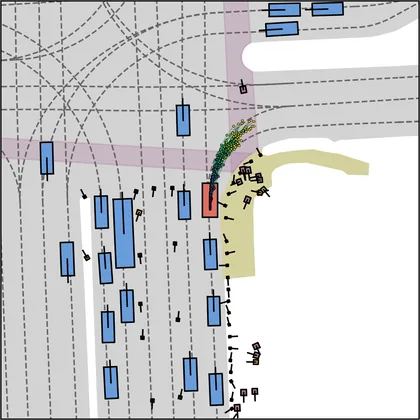 |  |
| DiffusionDrive | 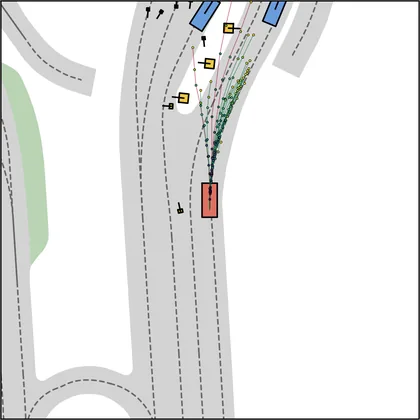 |  |
|---|---|---|
| DiffusionDriveV2 | 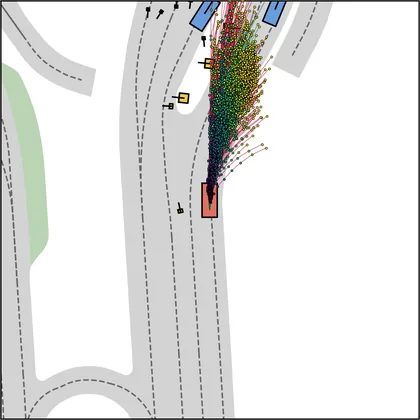 |  |
| iPad | 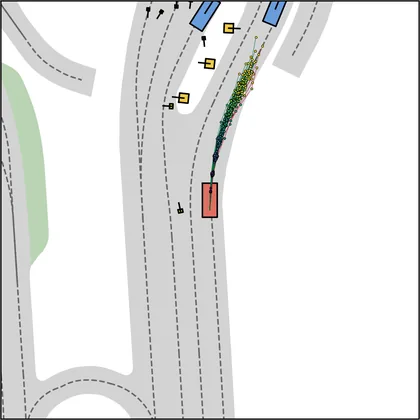 |  |
| FlowR2A (ours) | 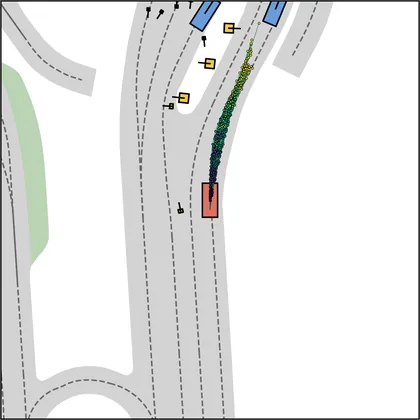 |  |
| DiffusionDrive | 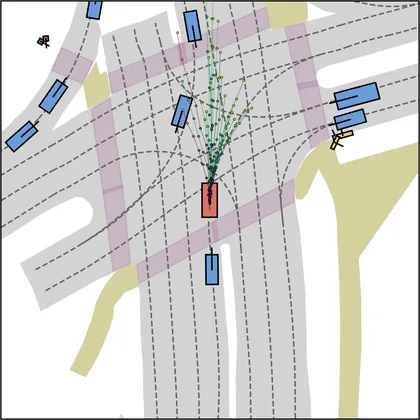 |  |
|---|---|---|
| DiffusionDriveV2 | 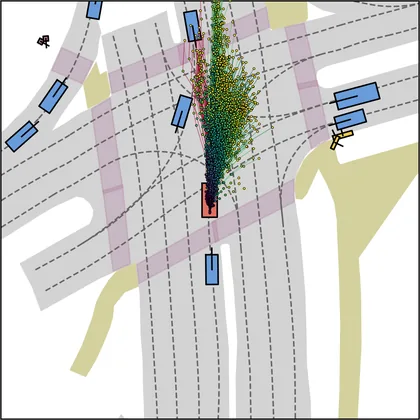 |  |
| iPad | 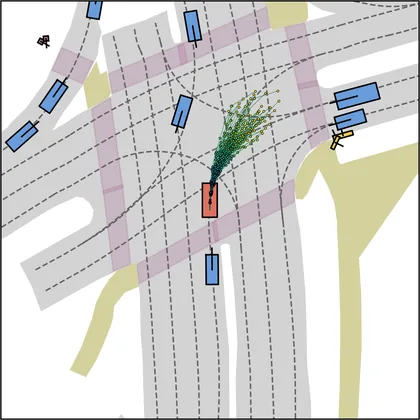 |  |
| FlowR2A (ours) | 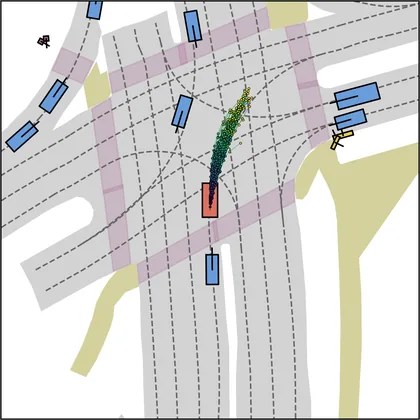 |  |
| DiffusionDrive | 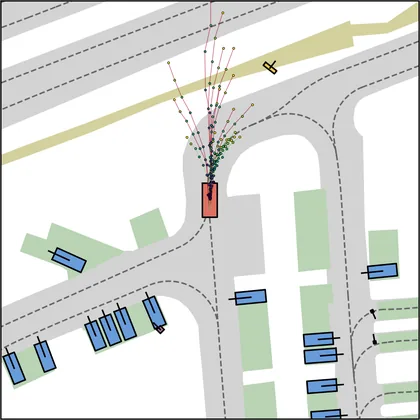 |  |
|---|---|---|
| DiffusionDriveV2 | 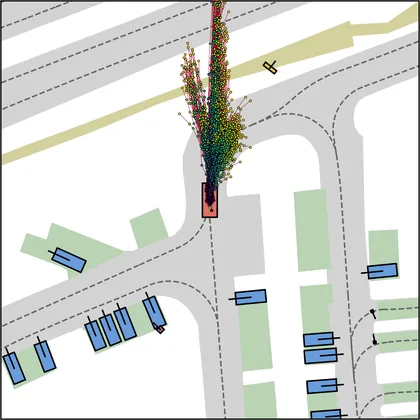 |  |
| iPad | 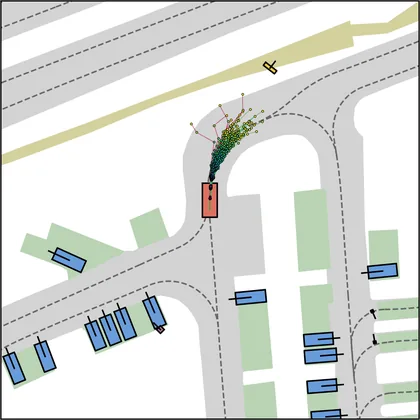 |  |
| FlowR2A (ours) | 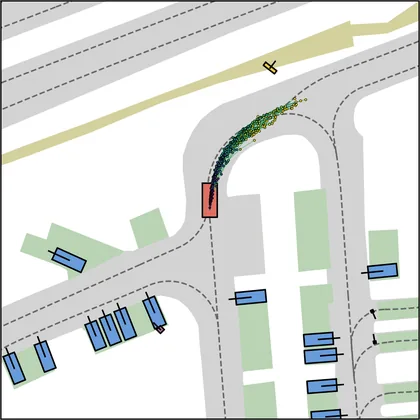 |  |
| DiffusionDrive | 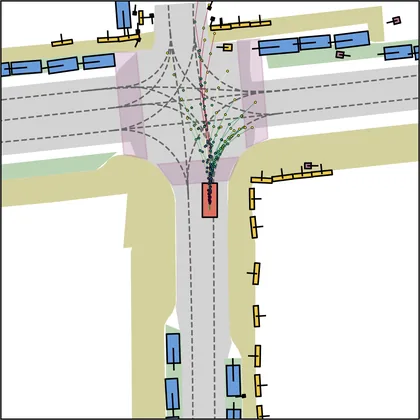 |  |
|---|---|---|
| DiffusionDriveV2 | 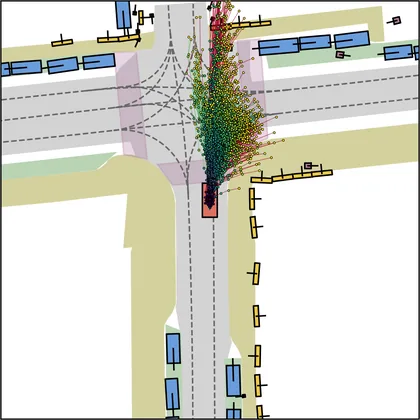 |  |
| iPad | 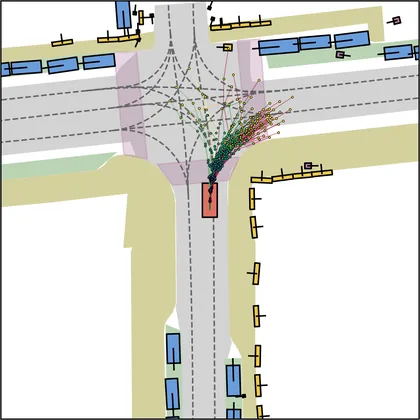 |  |
| FlowR2A (ours) | 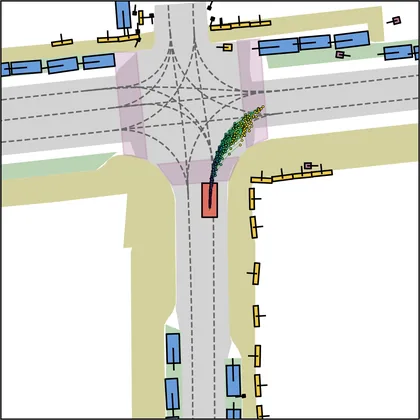 |  |
| DiffusionDrive | 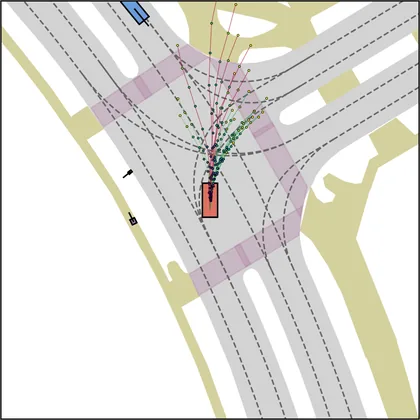 |  |
|---|---|---|
| DiffusionDriveV2 | 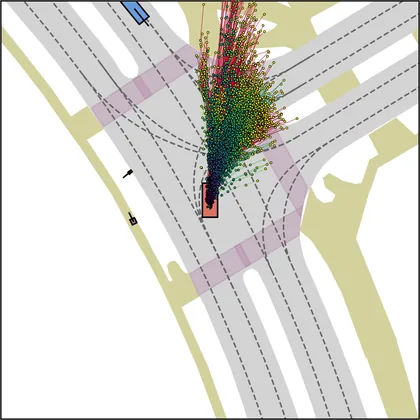 |  |
| iPad | 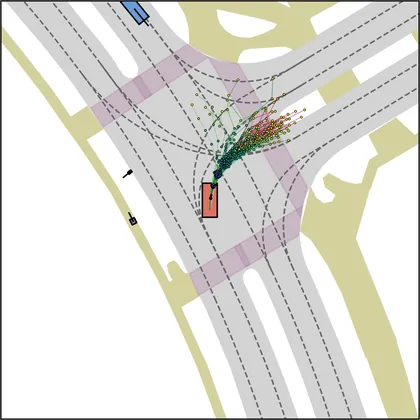 |  |
| FlowR2A (ours) | 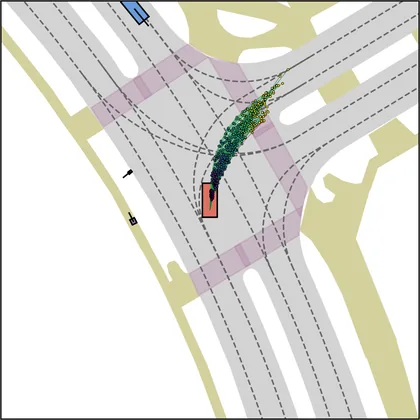 |  |
| DiffusionDrive | 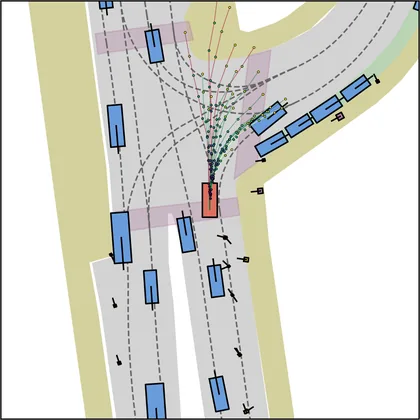 |  |
|---|---|---|
| DiffusionDriveV2 | 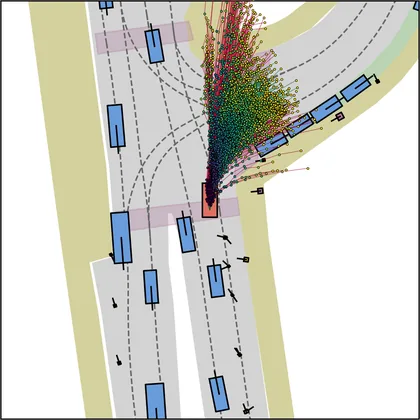 |  |
| iPad | 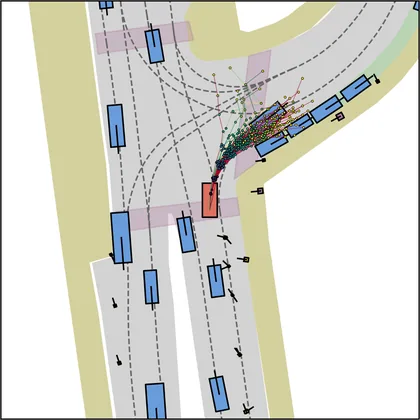 |  |
| FlowR2A (ours) | 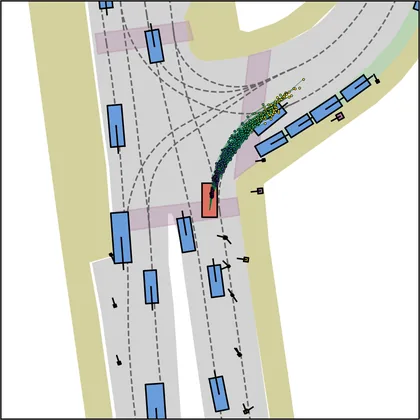 |  |
| DiffusionDrive | 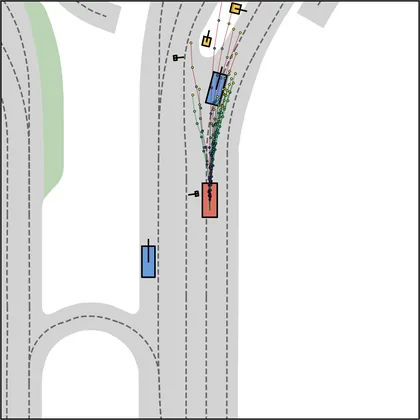 |  |
|---|---|---|
| DiffusionDriveV2 | 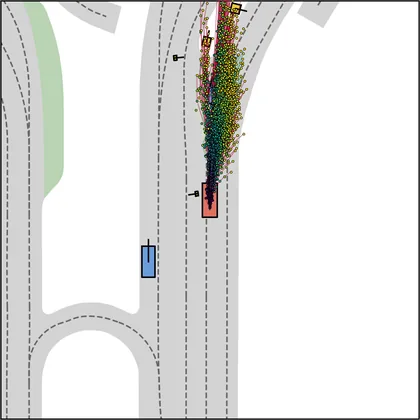 |  |
| iPad | 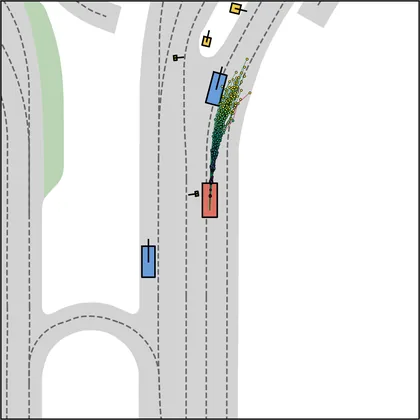 |  |
| FlowR2A (ours) | 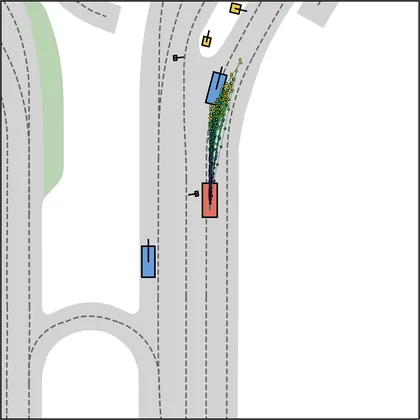 |  |
| DiffusionDrive | 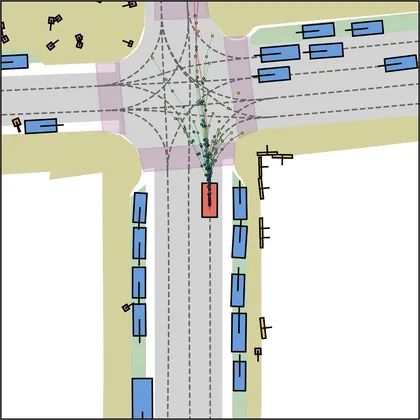 |  |
|---|---|---|
| DiffusionDriveV2 | 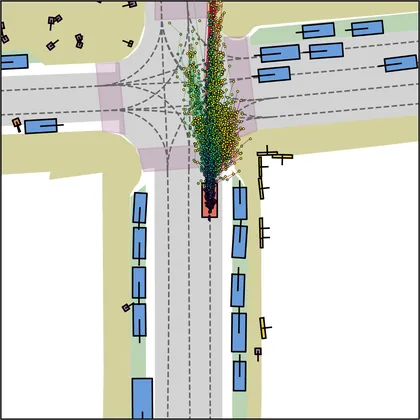 |  |
| iPad | 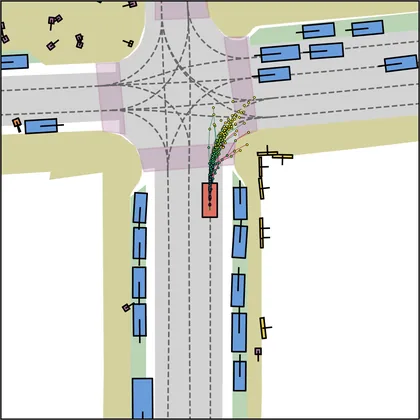 |  |
| FlowR2A (ours) | 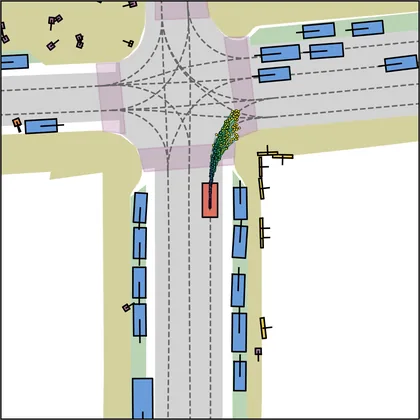 |  |
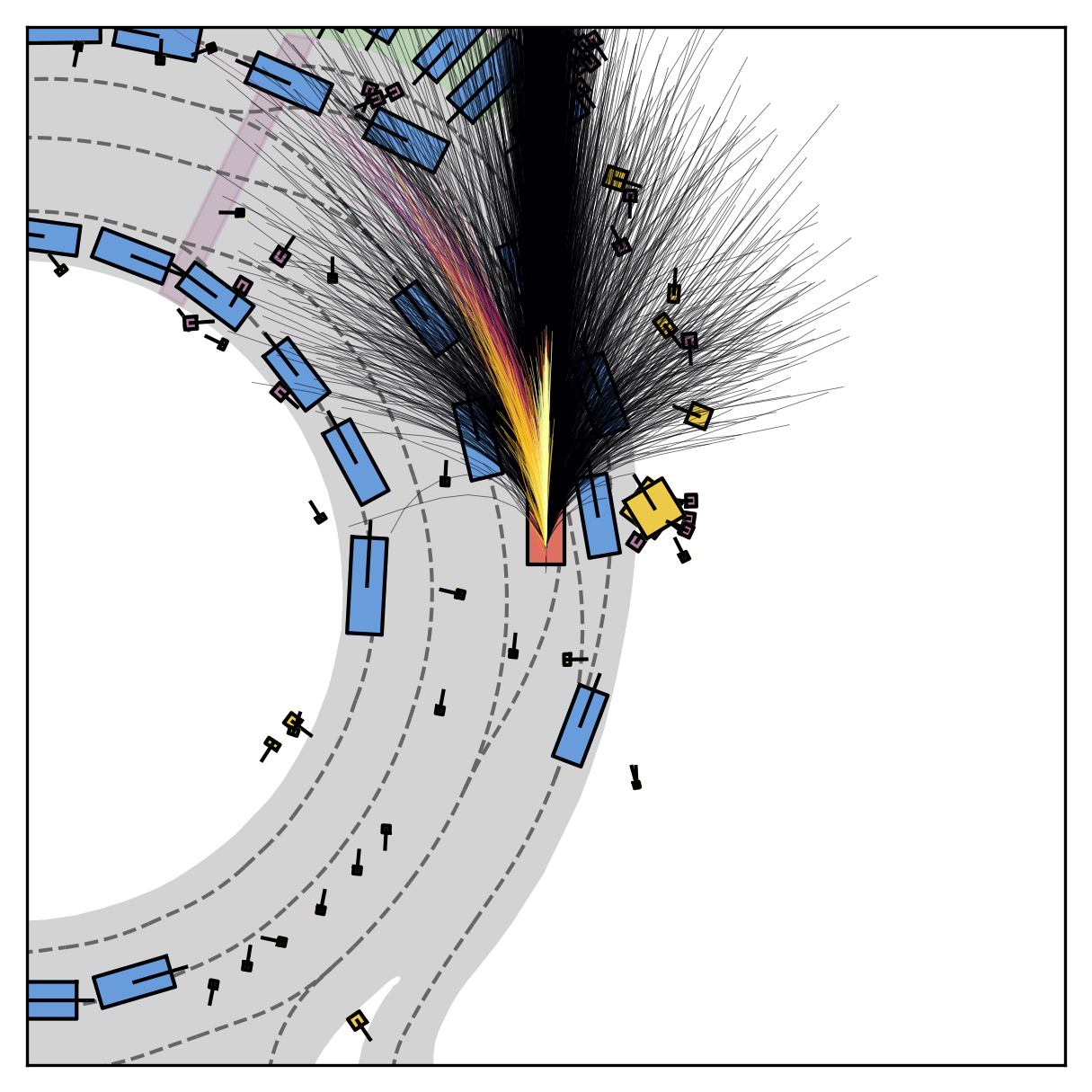
FlowR2A produces consistently high-quality proposal candidates, surpassing the prior multimodal planner iPad on both single and average proposal quality.
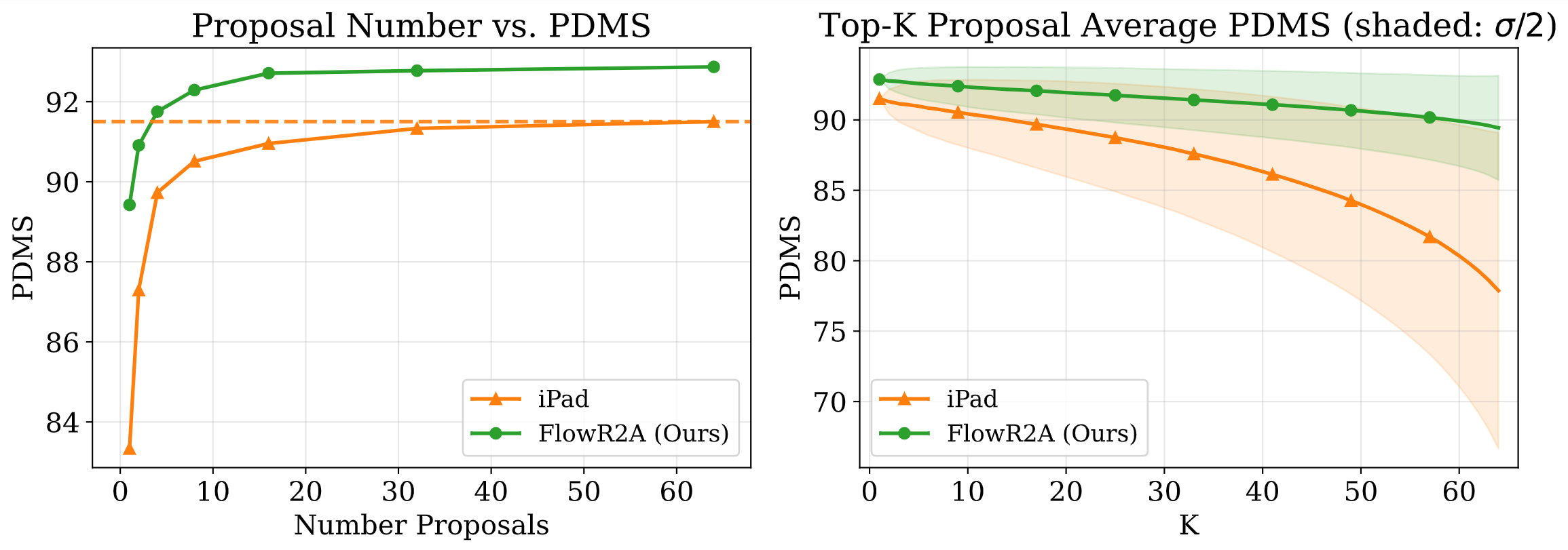
FlowR2A's top-K proposals dominate prior planners across K.
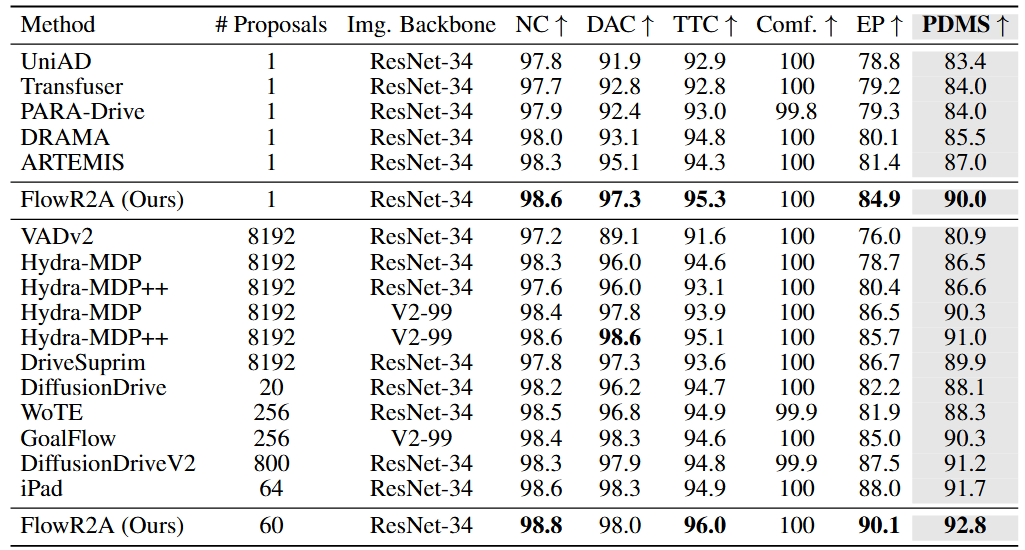
FlowR2A achieves state-of-the-art performance on the NAVSIM v1 navtest benchmark under a lightweight backbone.
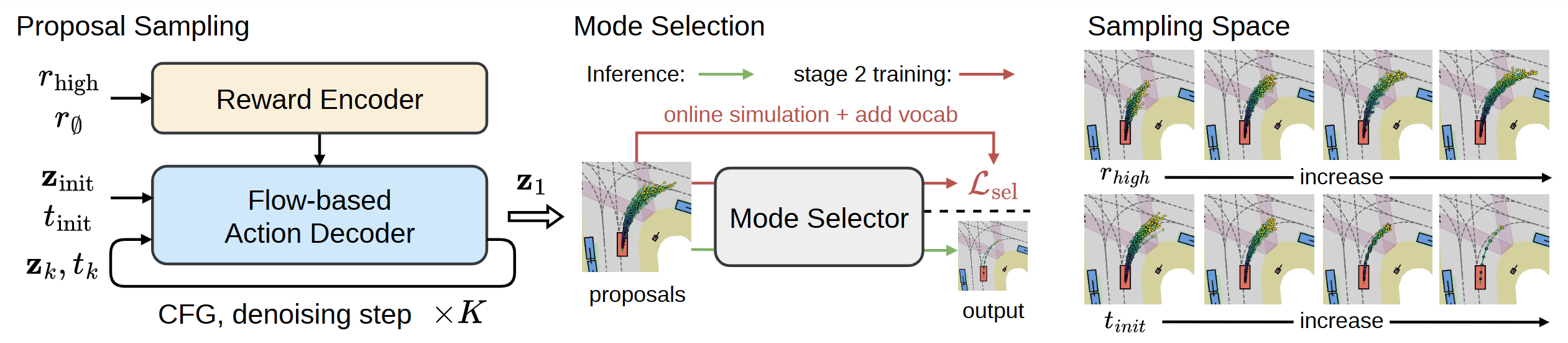
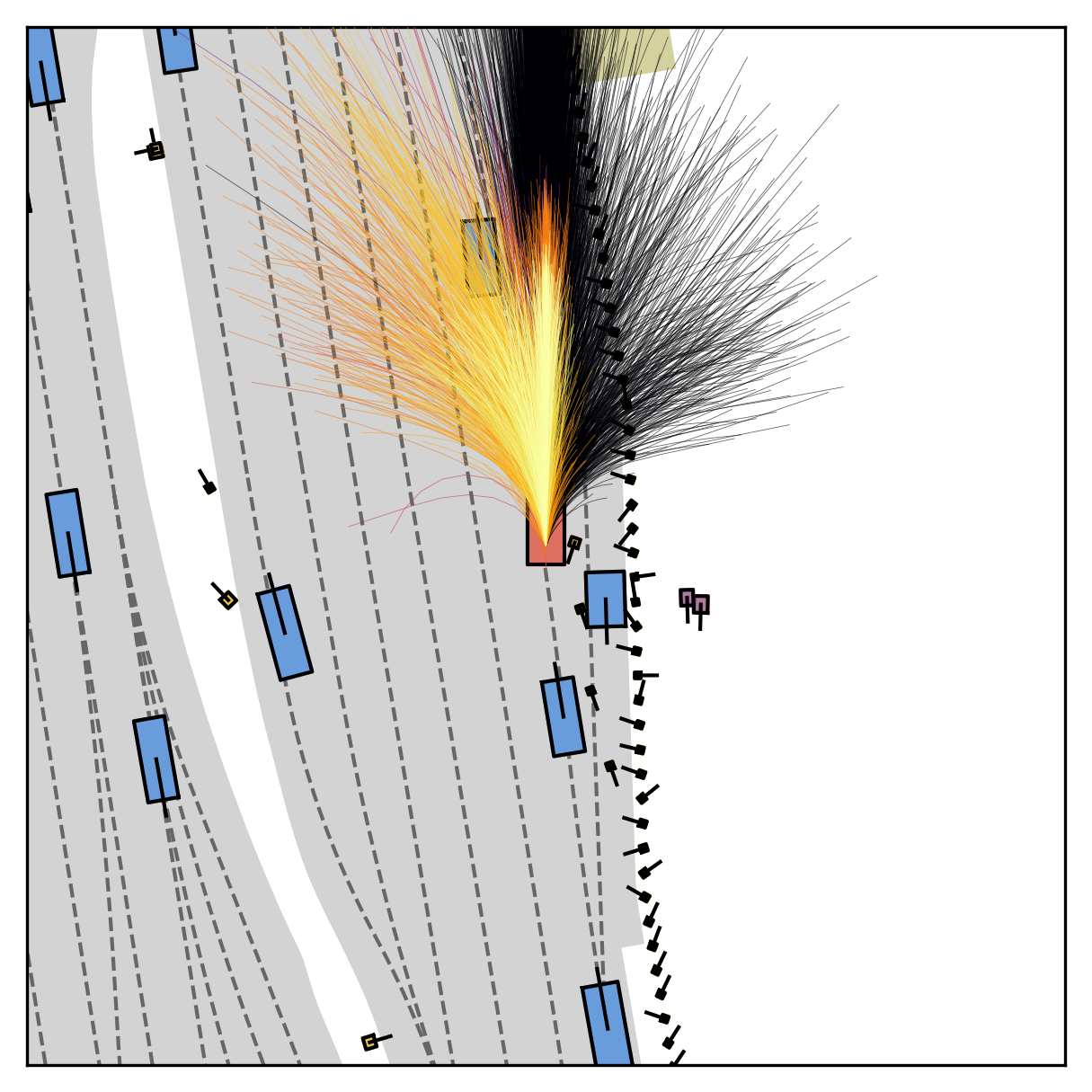
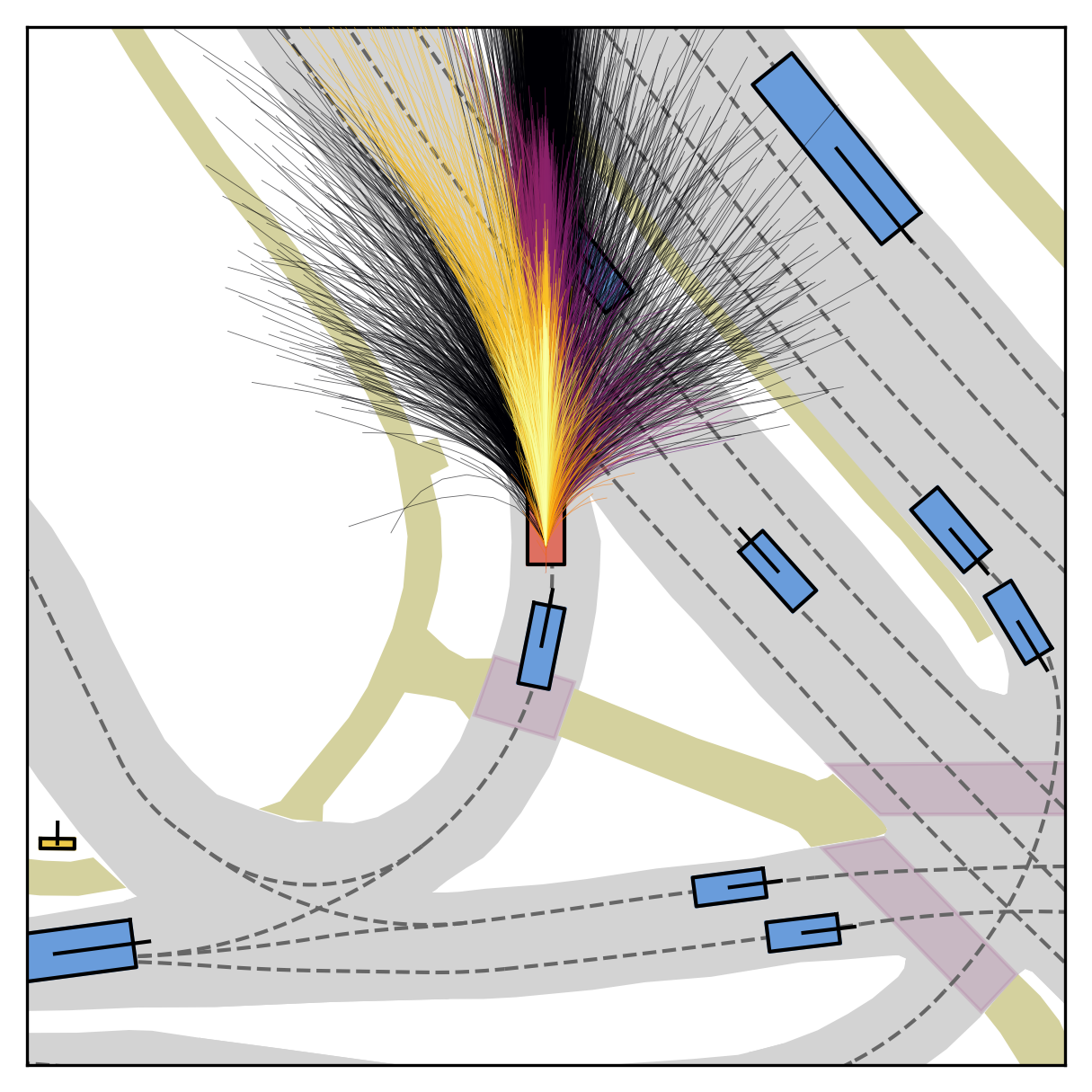
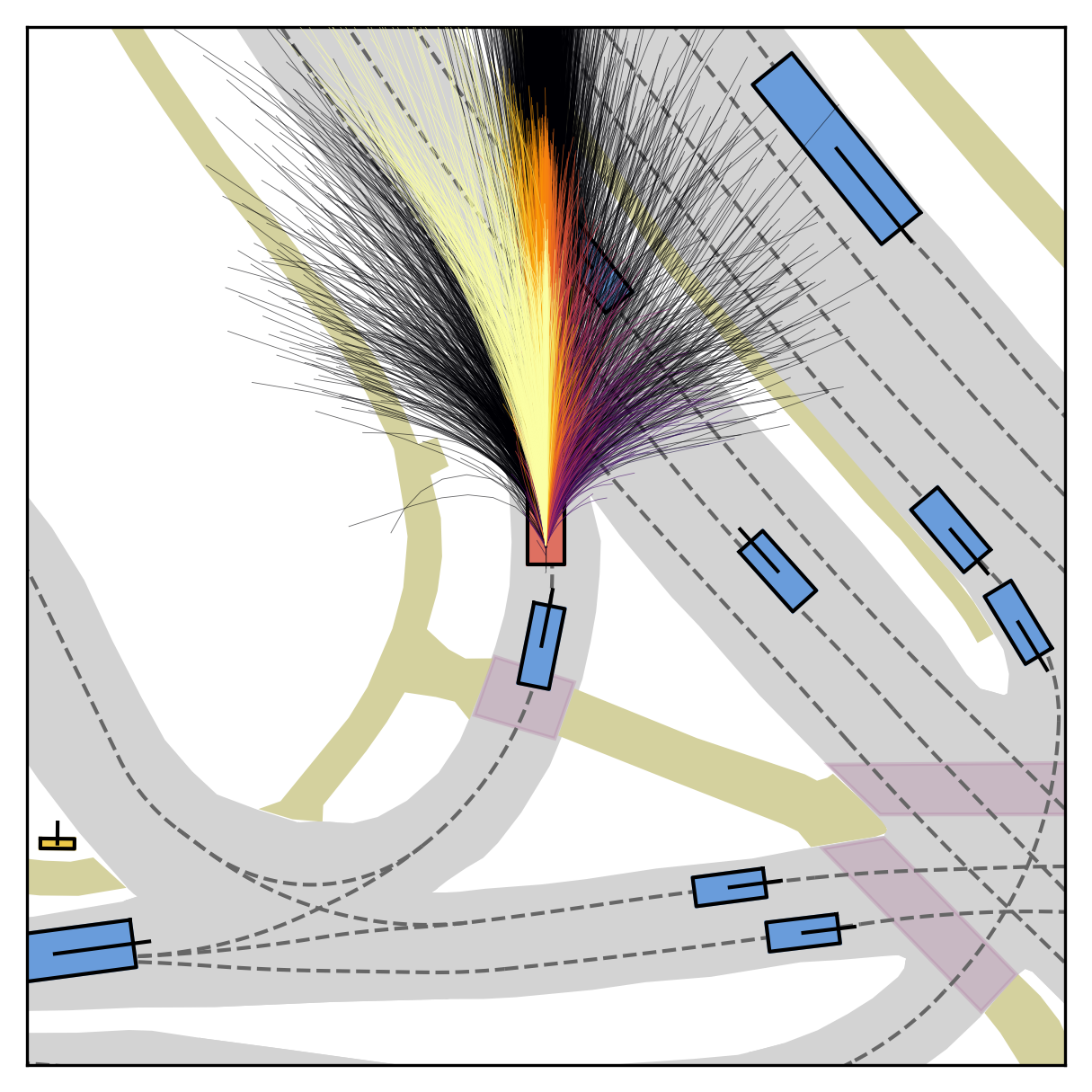
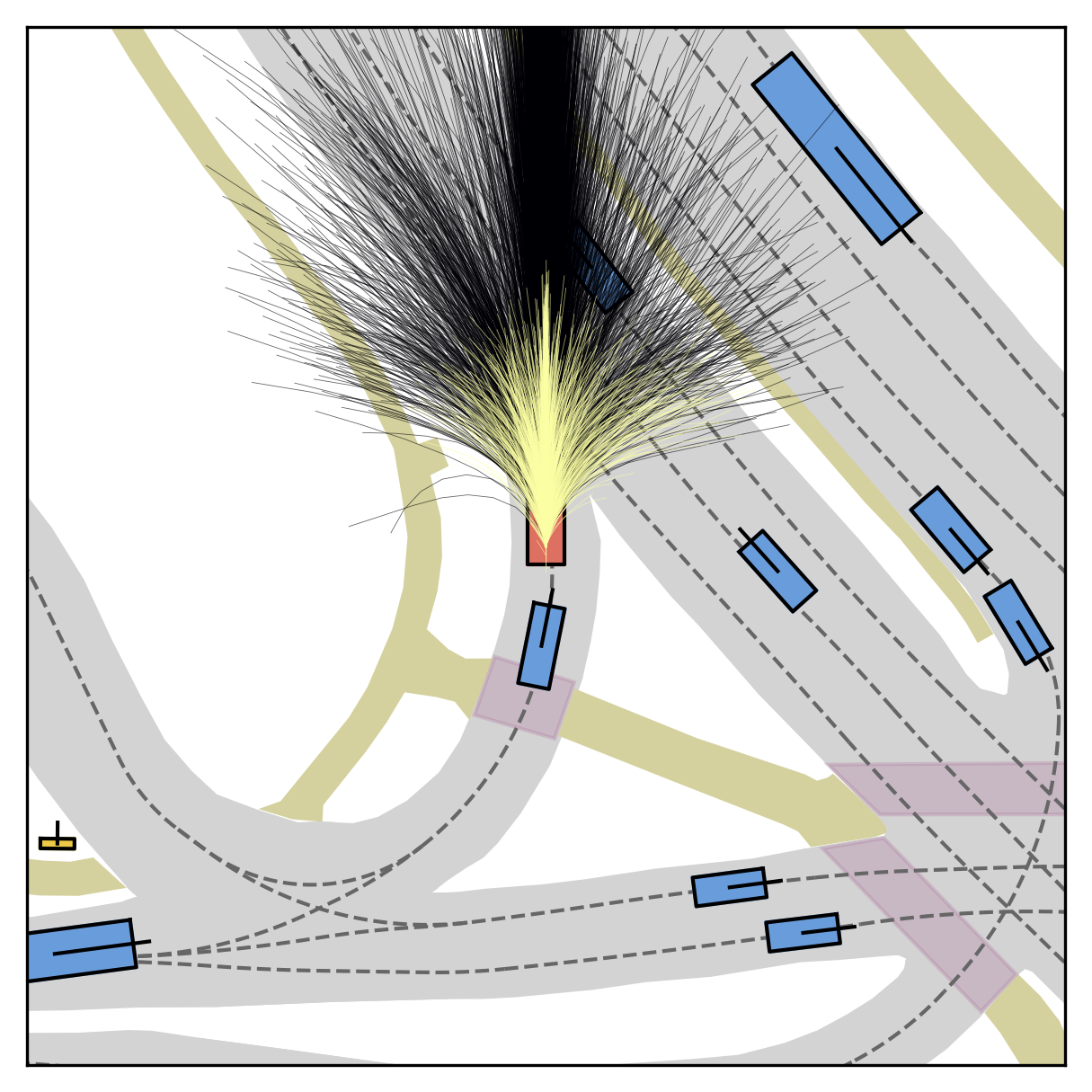
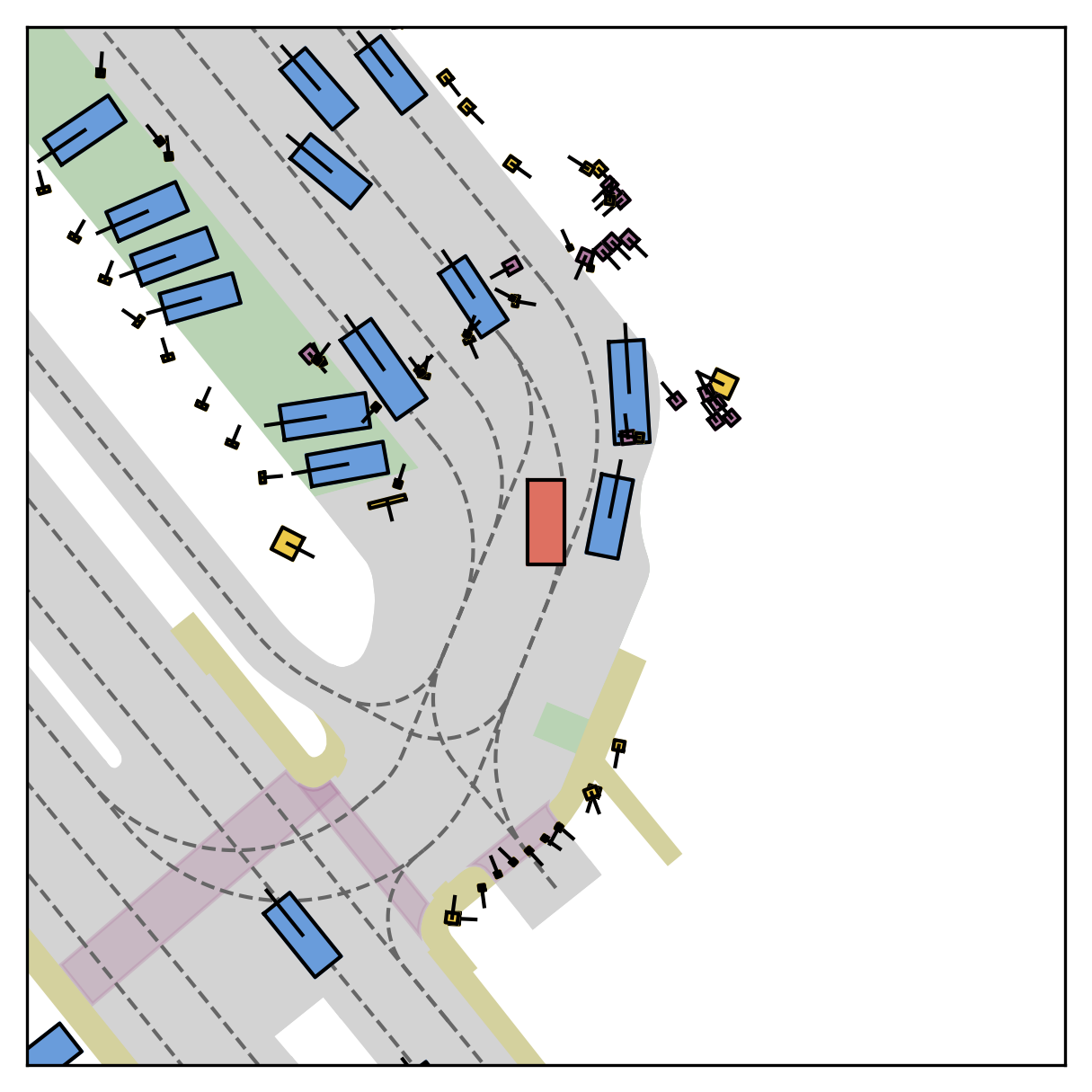
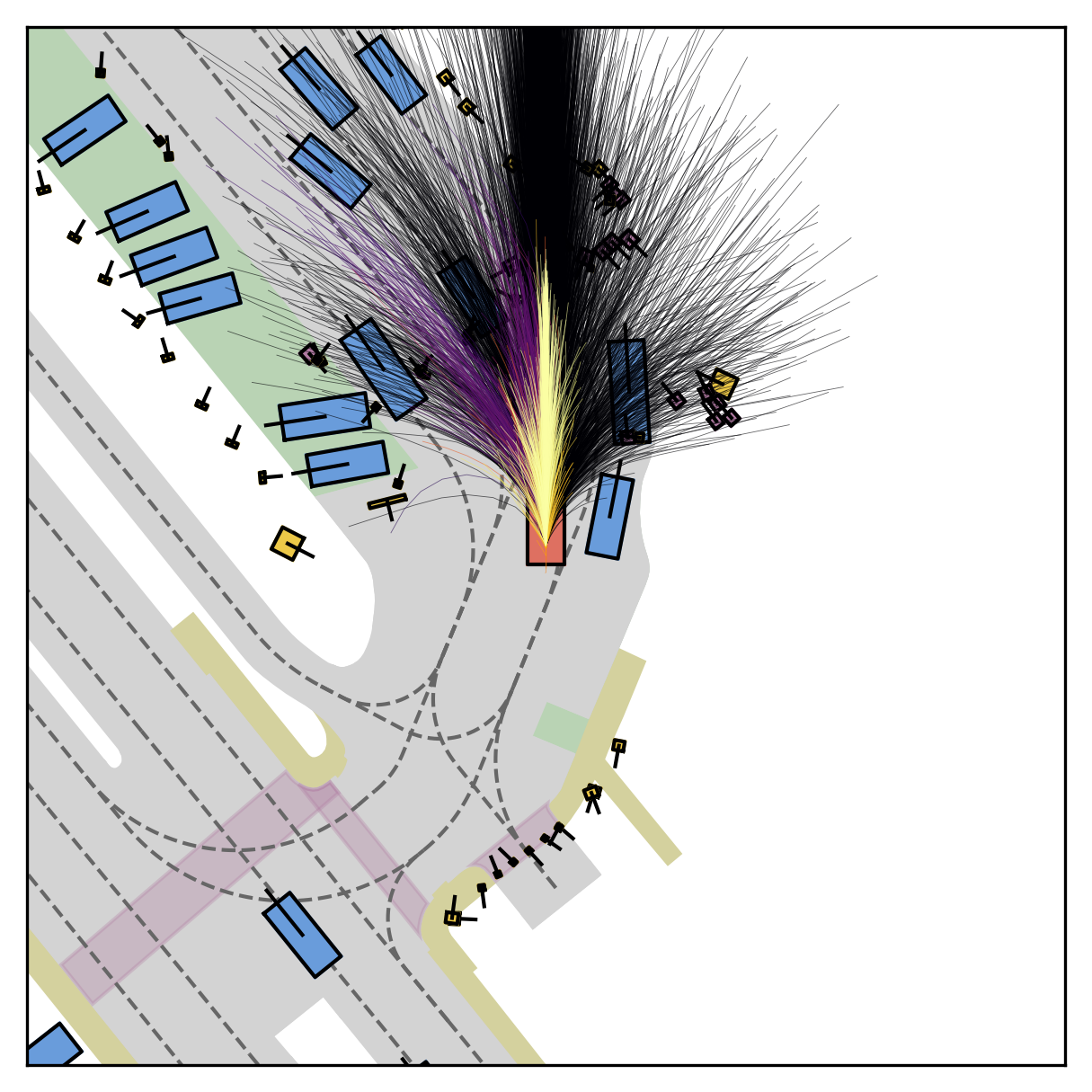
FlowR2A offers flexible sampling control through two intuitive knobs: a reward target rhigh steers proposals toward higher-PDMS regions, and an initial noise level tinit trades anchor fidelity for sampling diversity.
Higher rhigh guides proposals toward higher-reward regions; higher tinit introduces more sampling diversity around the anchor.
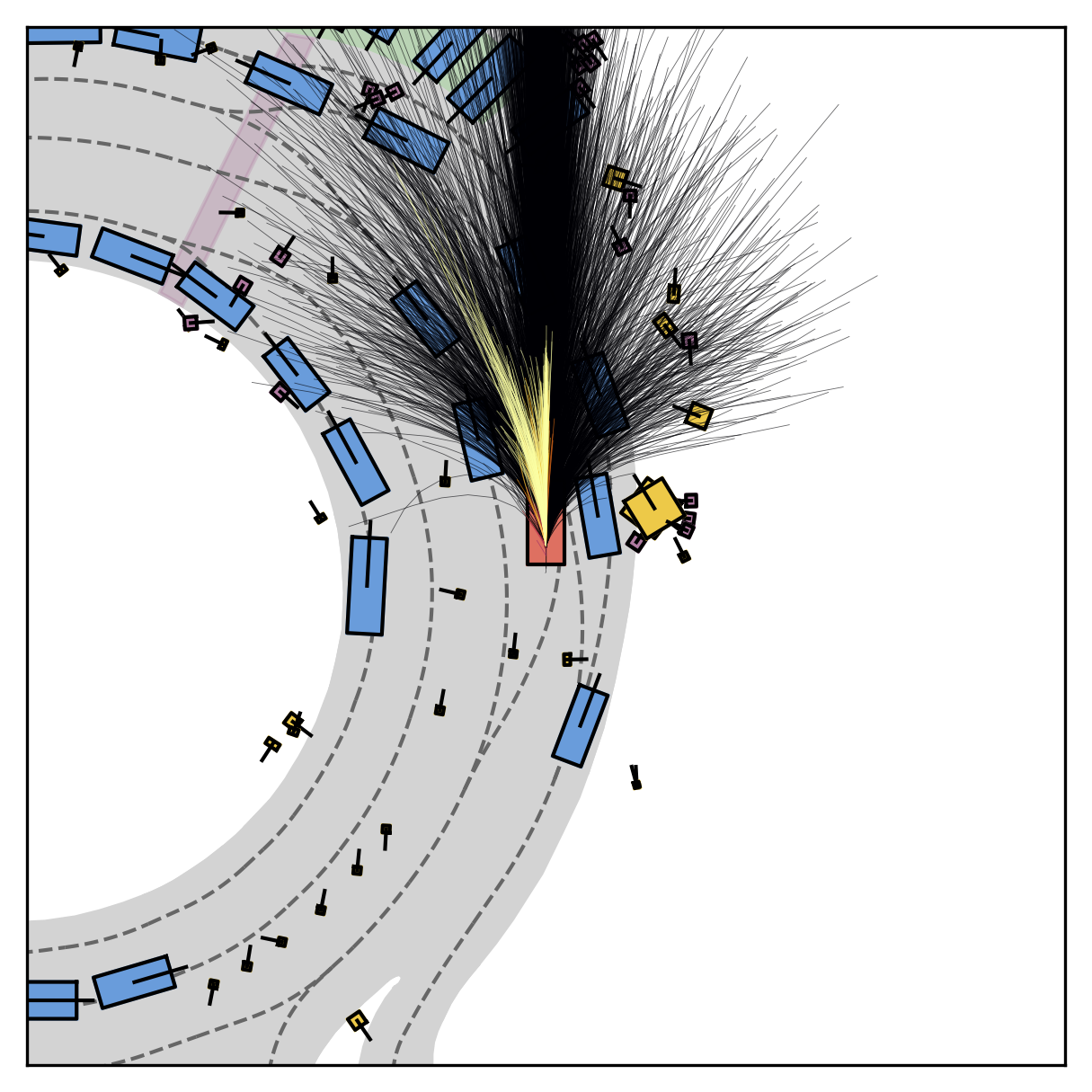
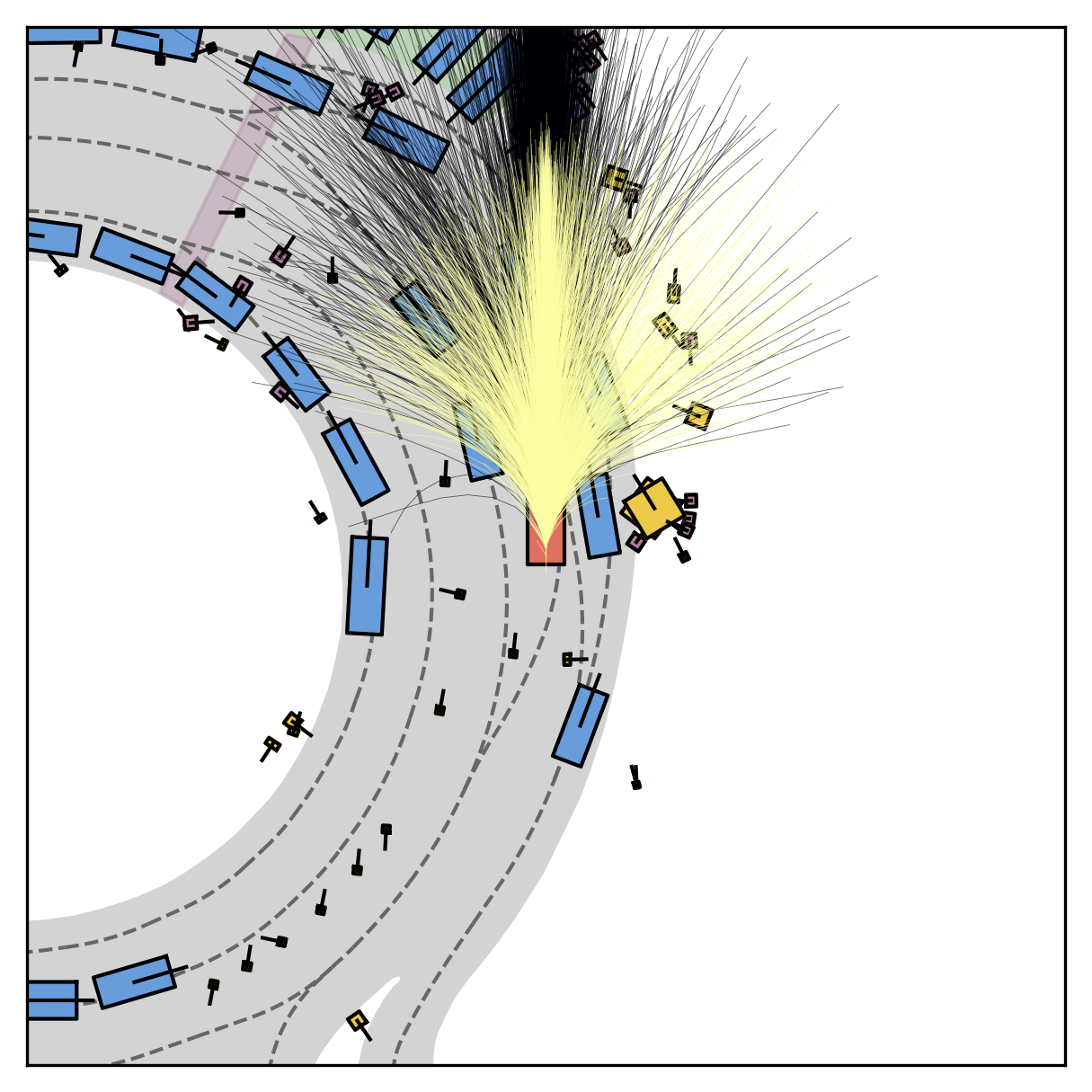
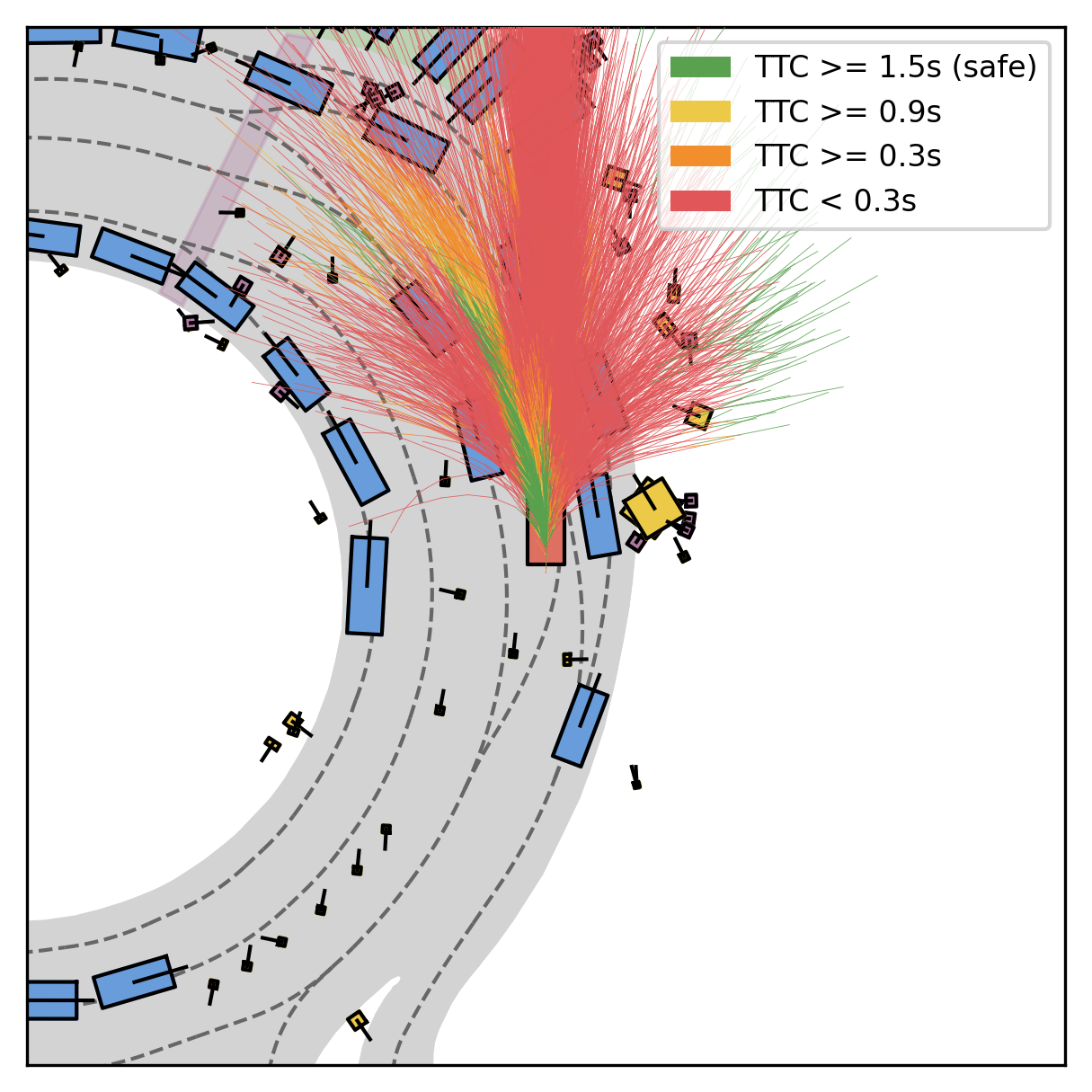
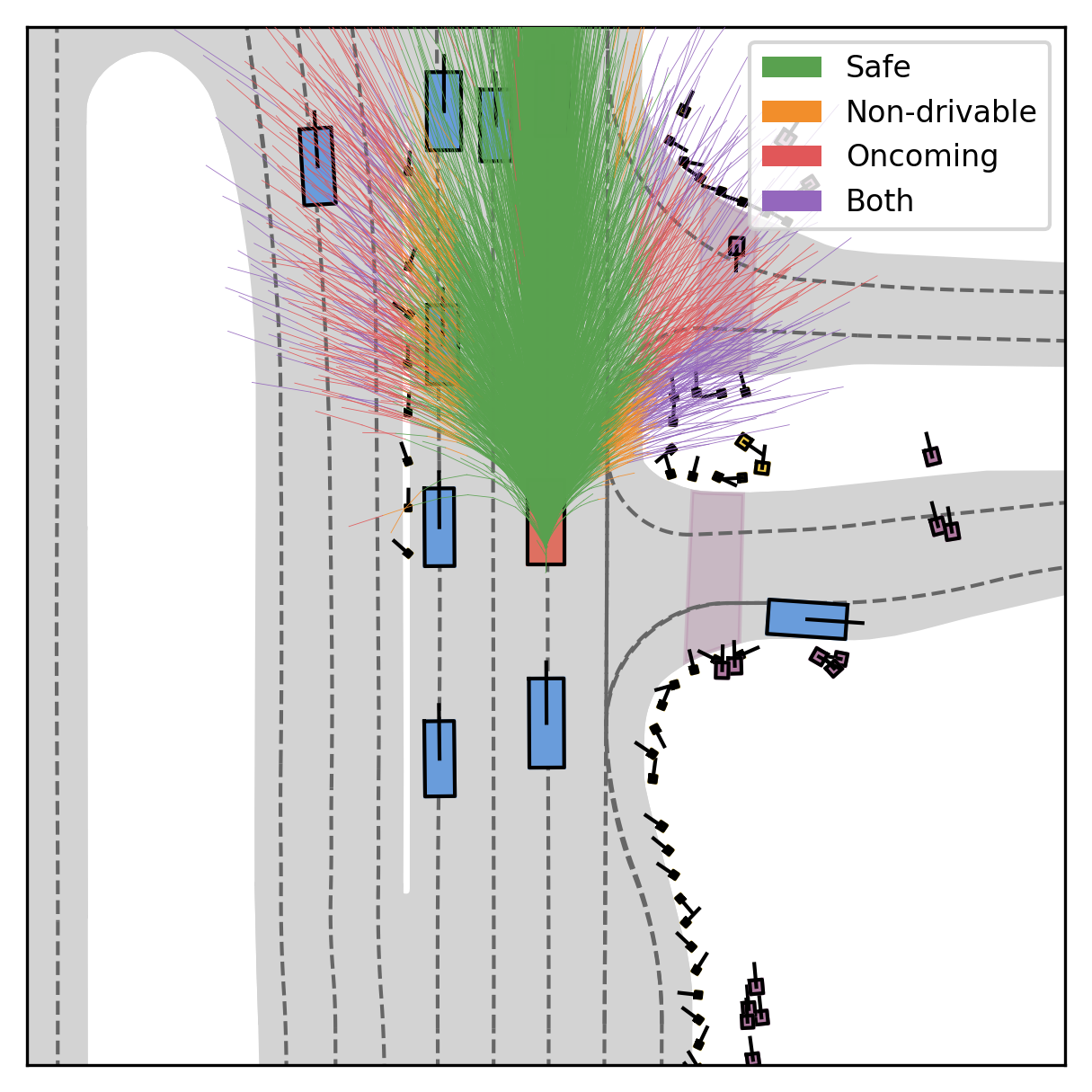
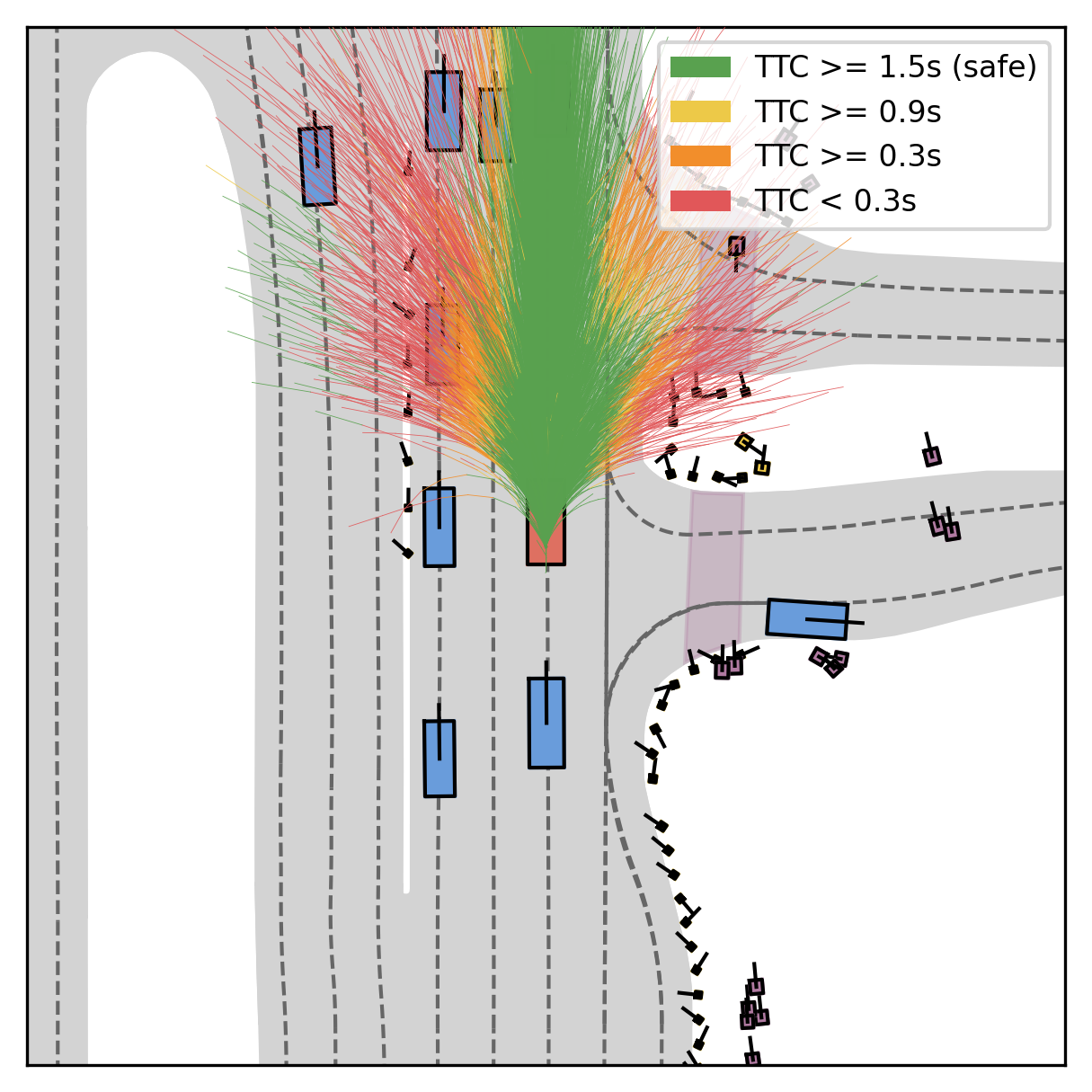
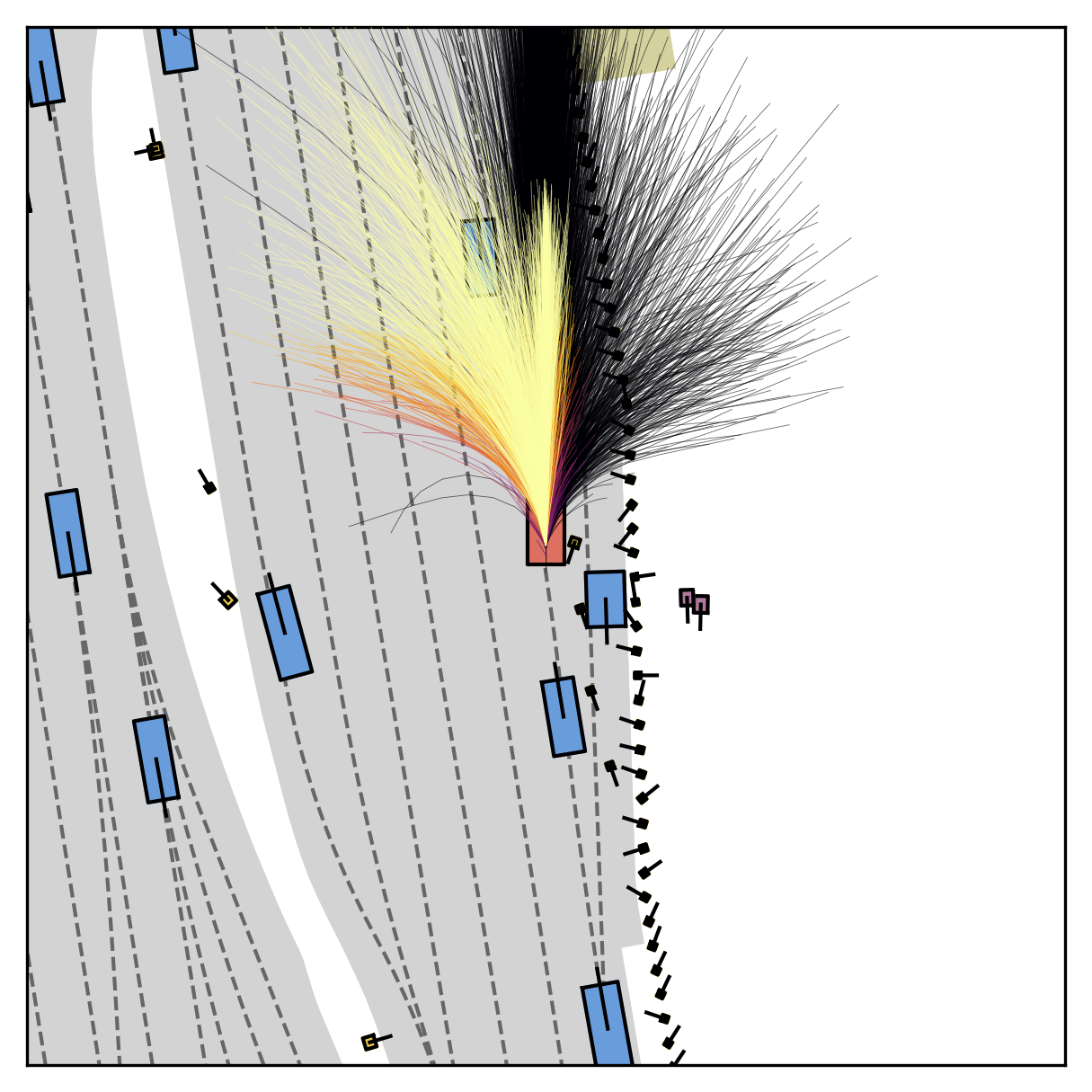
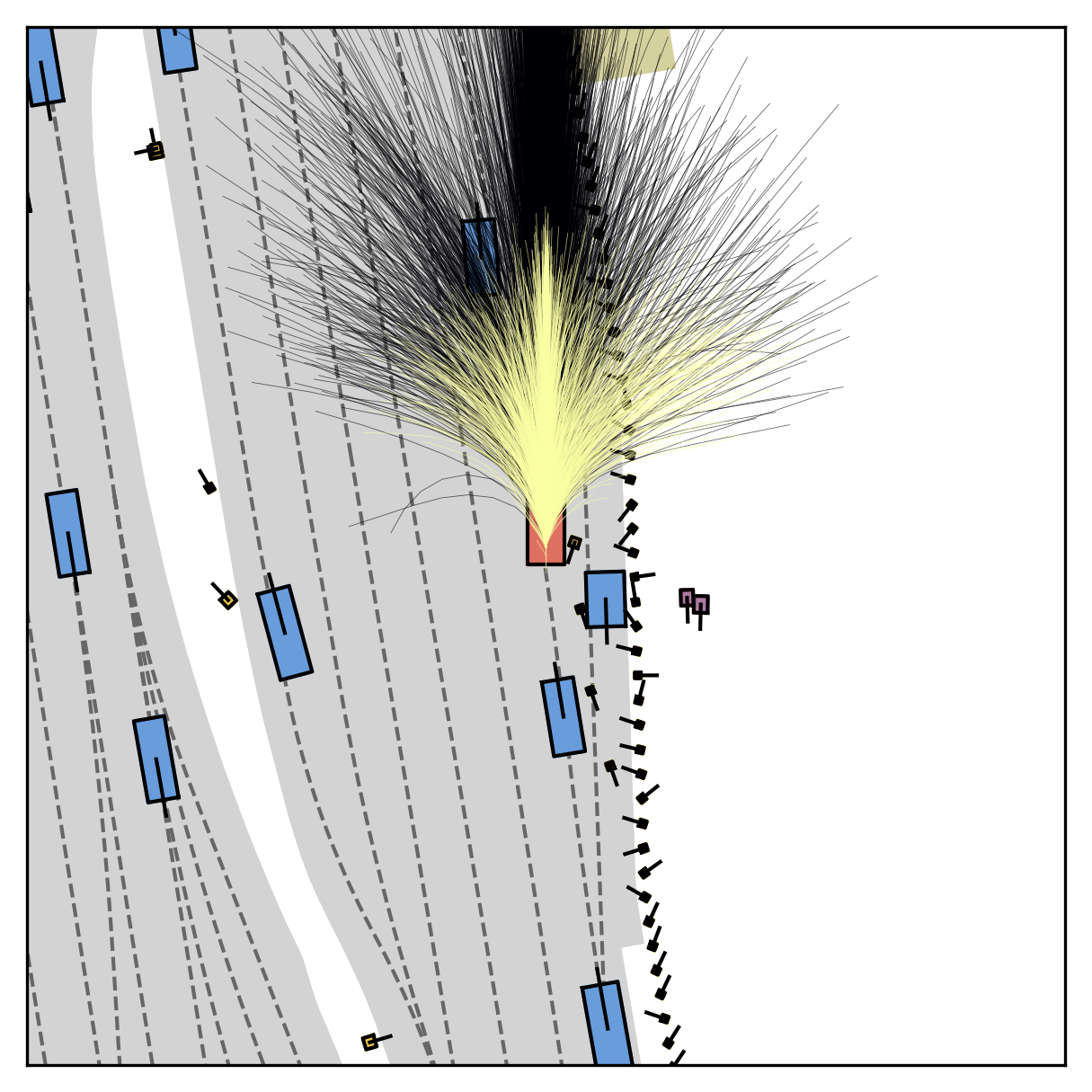
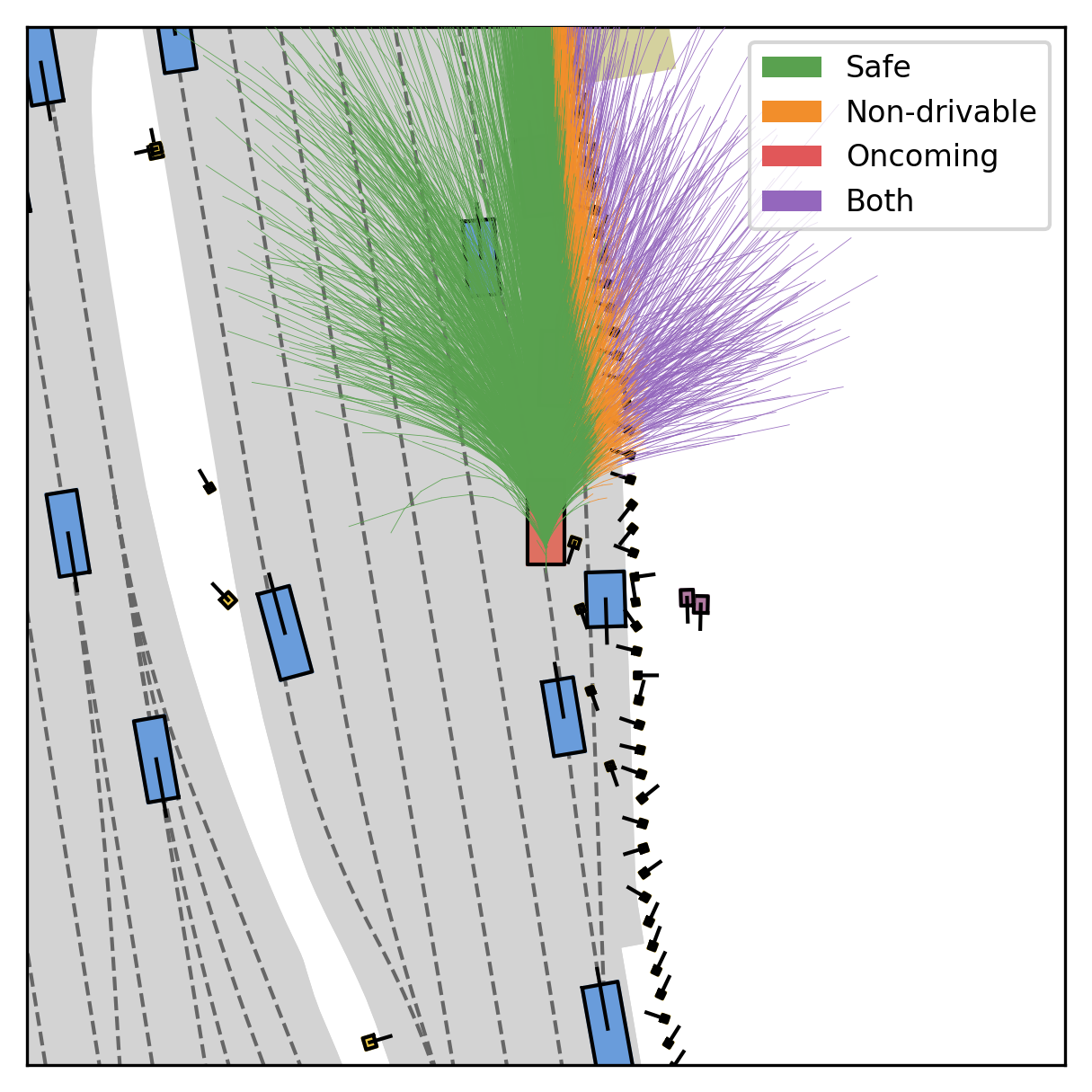
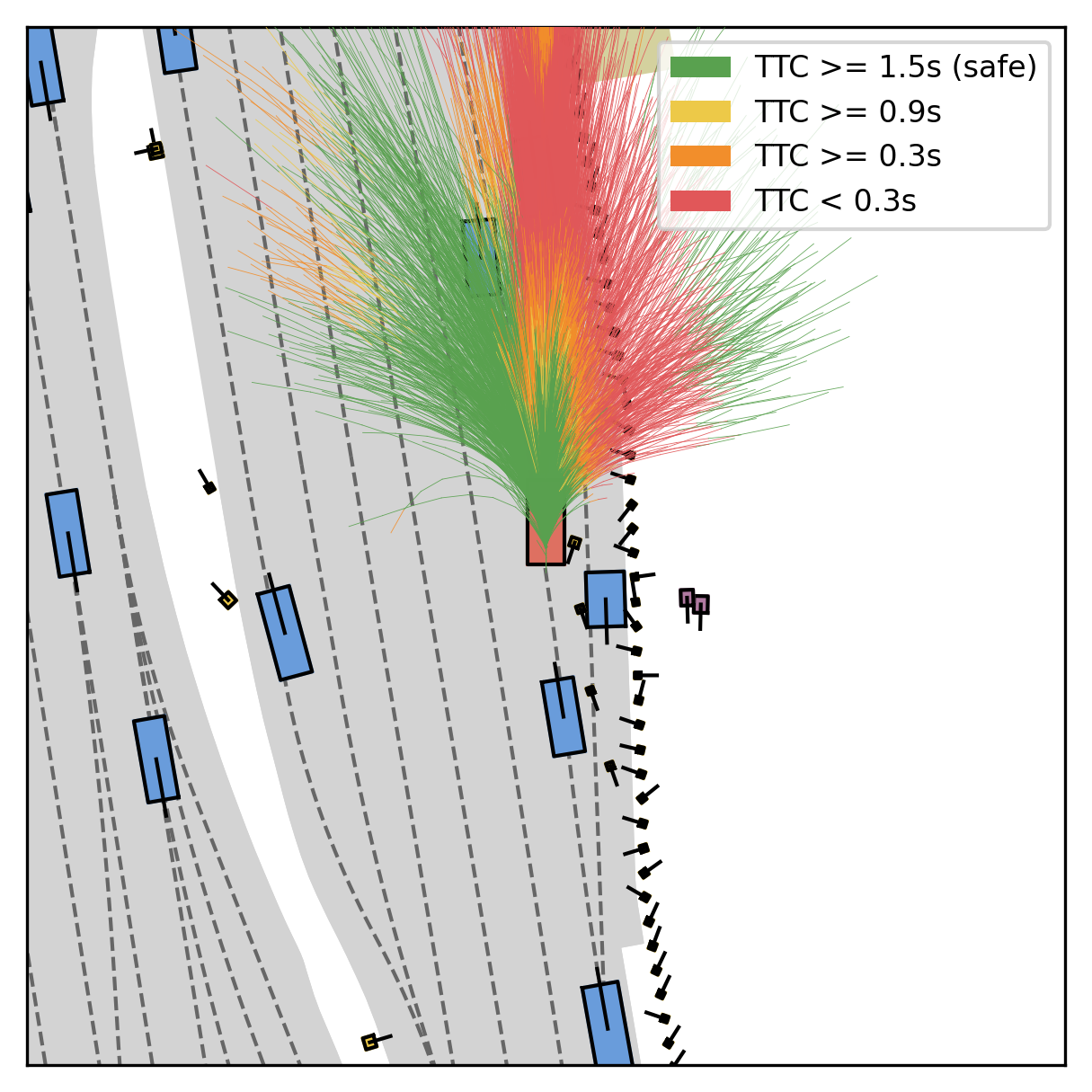
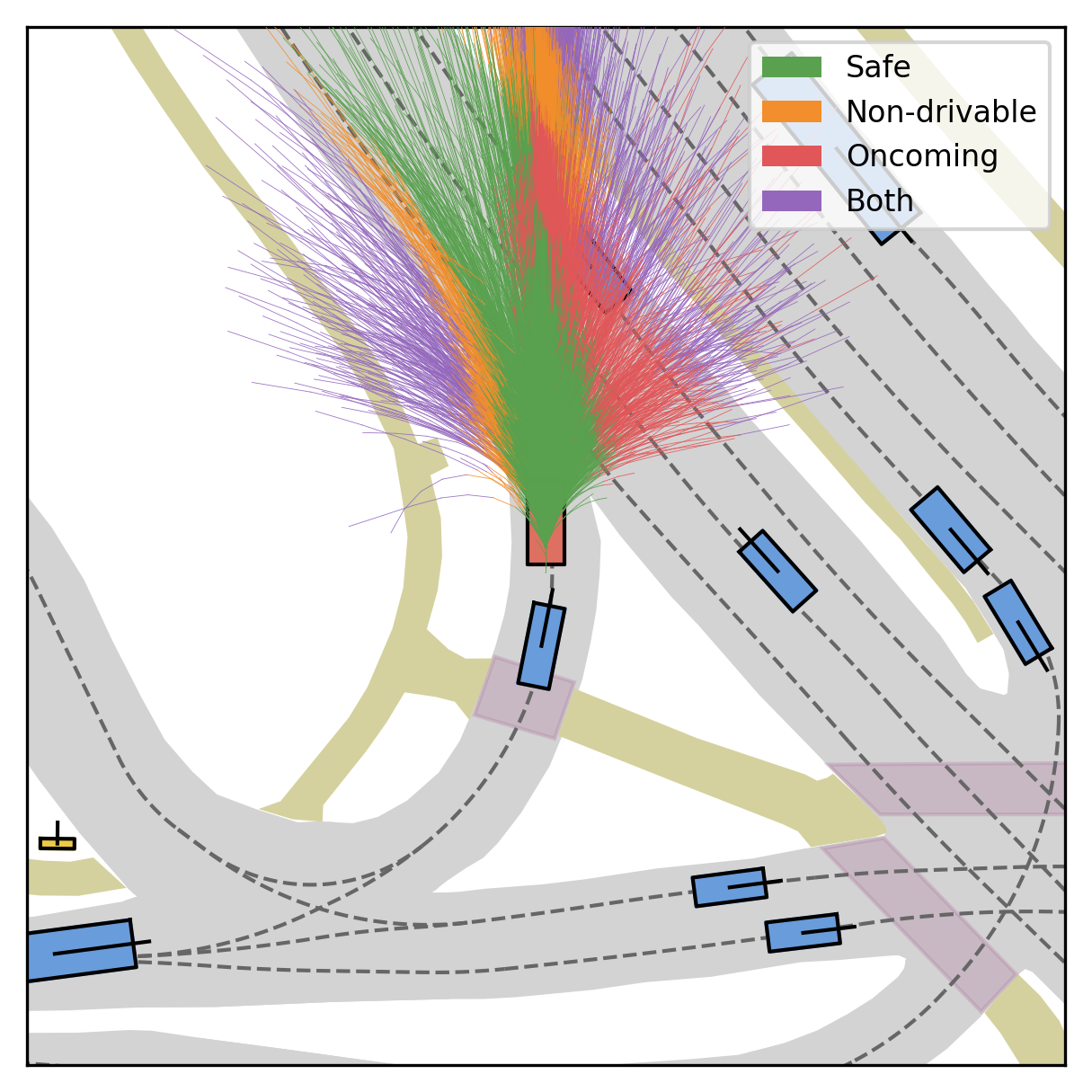
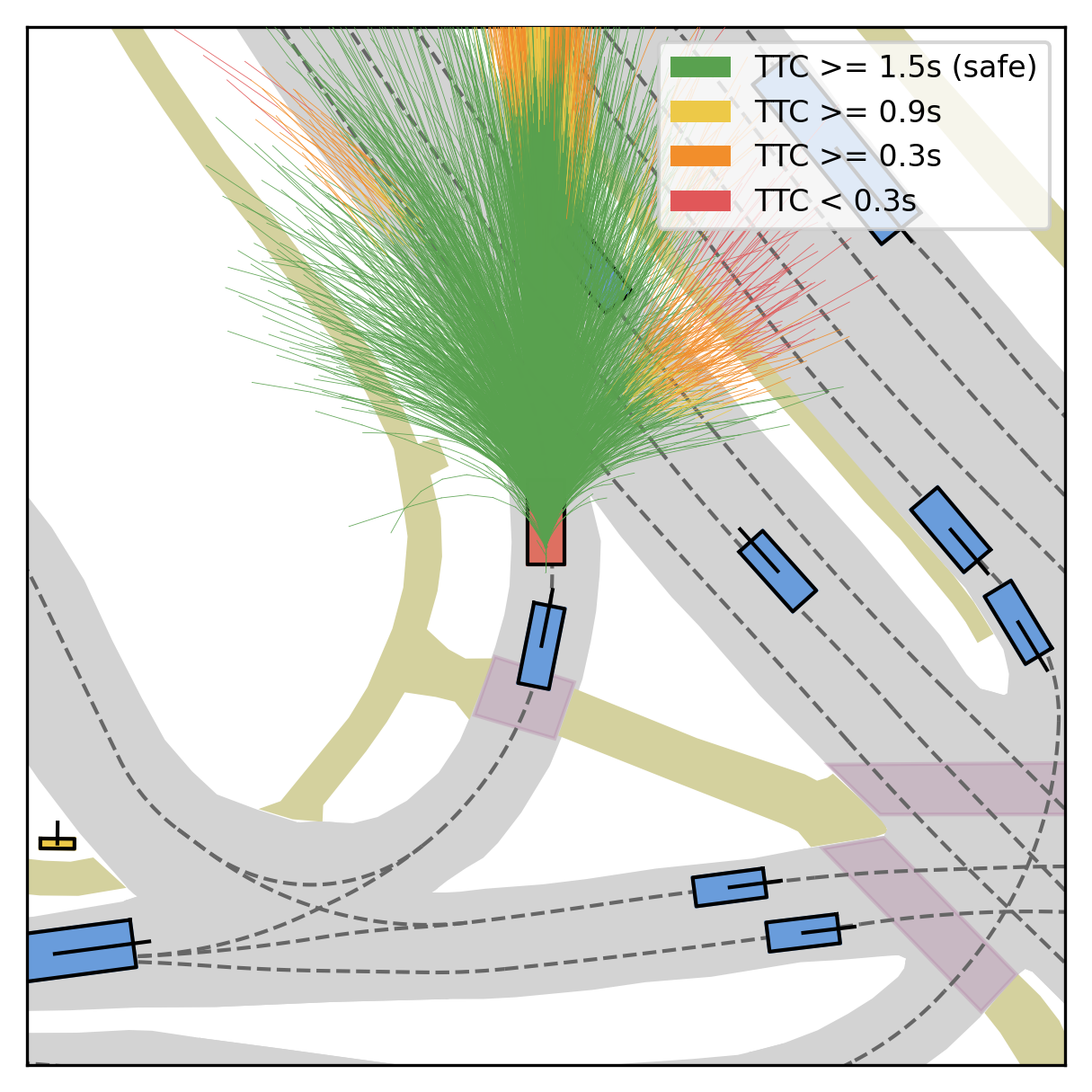
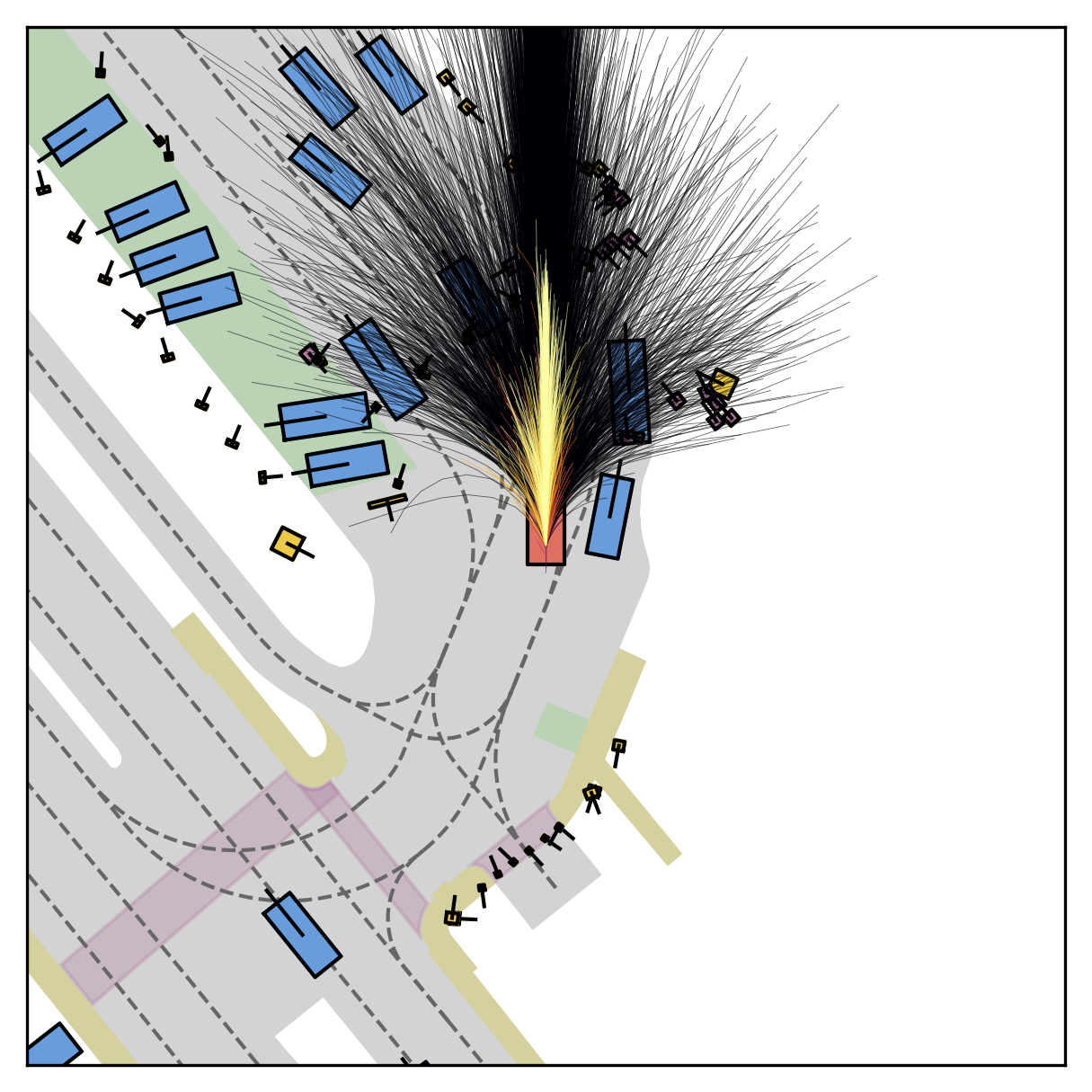
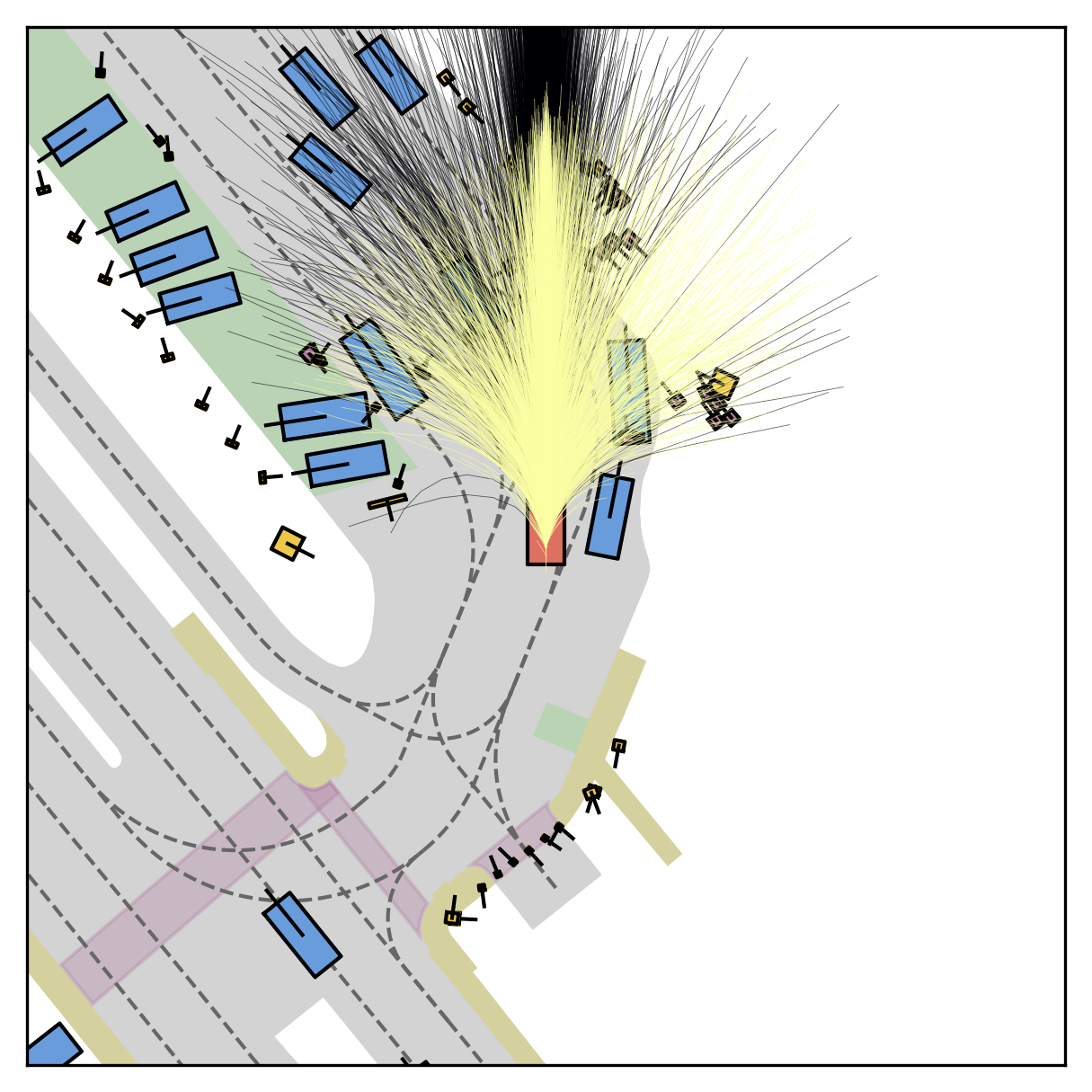
Fine-grained reward labels used in training partition dense trajectories in complementary ways, exposing rich signals for the model to internalize action-reward correlations.
@article{flowr2a2026,
title = {FlowR2A: Learning Reward-to-Action Distribution for Multimodal Driving Planning},
author = {Li, Xirui and Liu, Zhe and Ye, Xiaoqing and Han, Wenhua and Pan, Yifeng and Han, Junyu and Zhao, Hengshuang},
journal = {arXiv preprint arXiv:2606.24231},
year = {2026}
}