Xirui LiI am a Ph.D. student in the School of Computing and Data Science at The University of Hong Kong, advised by Prof. Hengshuang Zhao. Previously, I received my Master and Bachelor degrees in Computer Science from Shanghai Jiao Tong University, where I worked in the AI Institute with Prof. Chao Ma. |
|
ResearchI'm interested in computer vision, generative AI. I mainly focus on diffusion-based image and video generation. |
FlowR2A: Learning Reward-to-Action Distribution for Multimodal Driving PlanningXirui Li, Zhe Liu, Xiaoqing Ye, Wenhua Han, Yifeng Pan, Junyu Han, Hengshuang Zhao arXiv, 2026. arxiv / project page / code / A flow-matching planner that learns the reward-to-action distribution from dense trajectory-reward pairs for multimodal driving planning. |
|
UniCon: A Simple Approach to Unifying Diffusion-based Conditional GenerationXirui Li, Charles Herrmann, Kelvin C.K. Chan, Yinxiao Li, Deqing Sun, Chao Ma, Ming-Hsuan Yang ICLR, 2025. arxiv / project page / code / A simple, unified framework to handle diverse conditional generation tasks involving a specific image-condition correlation in one diffusion model. |
|
VidToMe: Video Token Merging for Zero-Shot Video EditingXirui Li, Chao Ma, Xiaokang Yang, Ming-Hsuan Yang CVPR, 2024. arxiv / project page / code / A zero-shot video editing method utilizing a pretrained image diffusion model. The key idea is to enforce video temporal consistency by merging self-attention tokens across frames. |
|
|
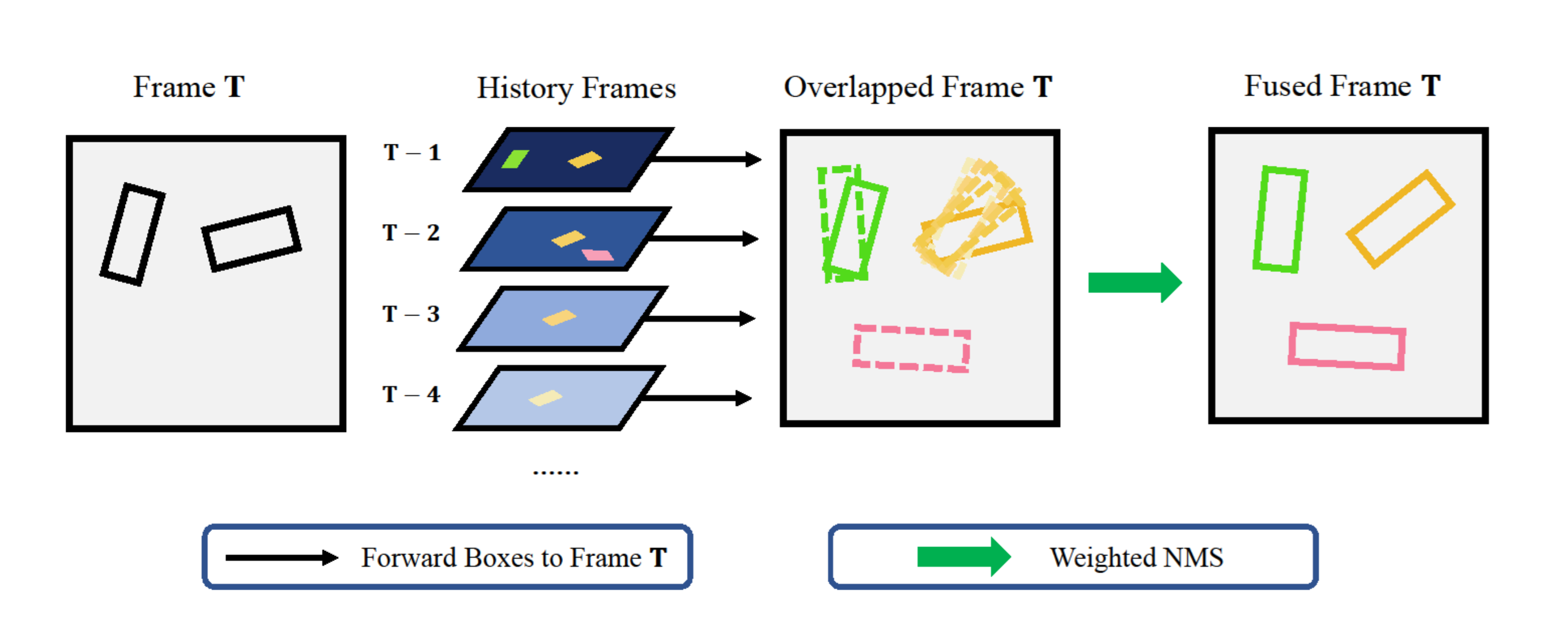
Frame Fusion with Vehicle Motion Prediction for 3D Object DetectionXirui Li, Feng Wang, Naiyan Wang, Chao Ma ICRA, 2024. arxiv / A detection enhancement method which improves 3D object detection results by forwarding and fusing history detection results. |
|
Built with the Jekyll fork by Leonid Keselman of Jon Barron's website. |